
Brandon Zhang
September 28, 2020
Process & Threads
Chapter 3: Process
3.1 Process Concept
3.1.1 Process Definition
A process is
- a program in execution
- the unit of resources (CPU, memory, I/O devices) allocation
- runs concurrently with other processes
Another definition: 具有一定独立功能的某个程序关于某个数据集合的一次运行活动。是系统进行资源分配和调度的独立单位。(又称task,job)
进程的特点:
- 动态性:可动态地创建、结束进程
- 并发性:进程可以被独立调度并占用处理机运行(并发&并行)
- 独立性:不同进程的工作不相互影响
- 制约性:因访问共享数据/资源或进程同步而产生制约(进程之间有交互、共享等情况)
Process = program + data + PCB.
3.1.2 Process State
A process is dynamic, and has its lifetime. As a process executes, it changes among the following states:
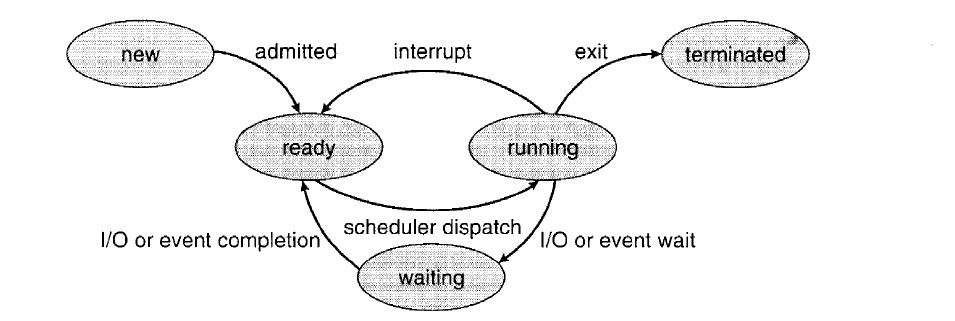
- new: the process is being created.
- ready: the process is waiting to be assigned to a process.
- running: instructions are being executed.
- waiting: the process is waiting for some event to occur.
- terminated: the process has finished execution.
3.1.3 Process Control Block
- Def: a data structure used for OS to describe processes, according to which OS manages processes.
操作系统用于管理控制进程的一个专门数据结构 进程表:所有进程的PCB集合
- Organization:

- process state: running, waiting, etc.
- program counter: location of instruction to next execute
- CPU registers: contents of all process-centric registers
- CPU scheduling information: priorities, scheduling queue pointers
- memory-management information: locations the process resides in the memory
- accounting information
- I/O status information
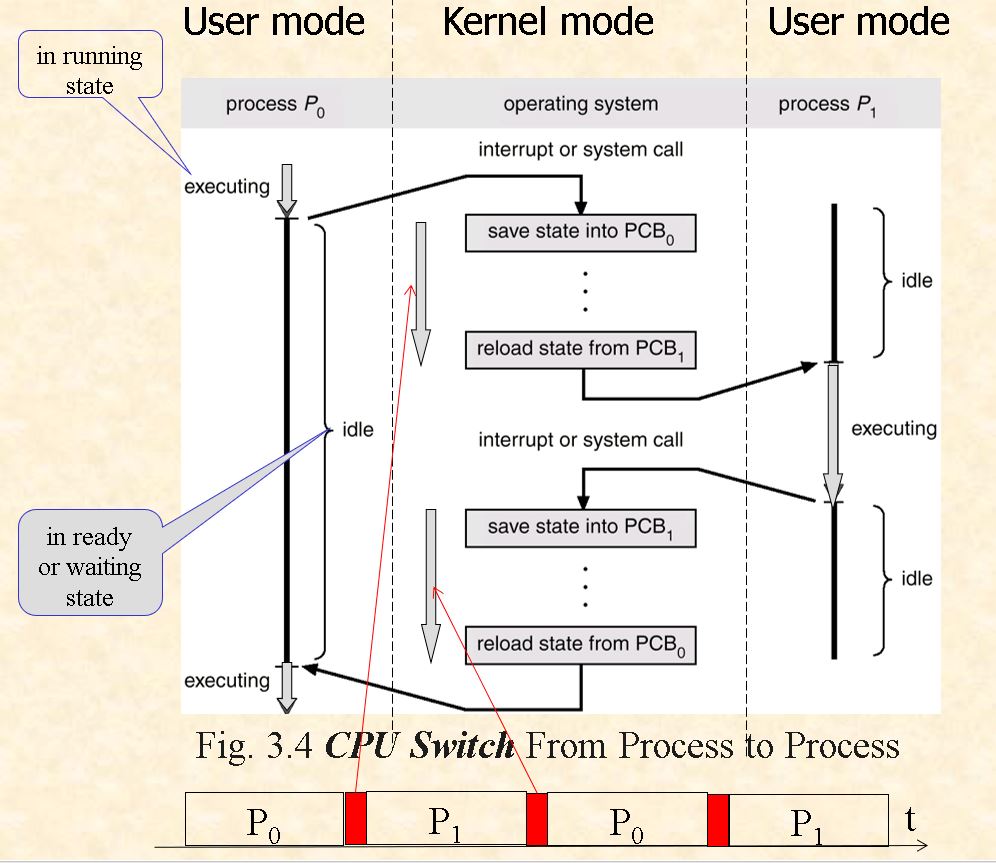
这张图清楚地表示了不同进程和系统调用的转换关系,以及在操作系统kernel mode中利用PCB保存进程现场的过程。从系统效率来看,引入线程的概念会大大增加系统运行的效率,若多进程工作,这种mode的转换很浪费计算机的资源。
3.2 Processing Schedule
3.2.1 Scheduling Queues
a series of processes waiting for being allocated some type of resources by OS schedulers, including
- ready queue the set of all processes residing in main memory, ready and waiting to execute, i.e. waiting for CPU.
- device queue the set of processes waiting for an I/O device.
- job queue
the set of all processes in the system.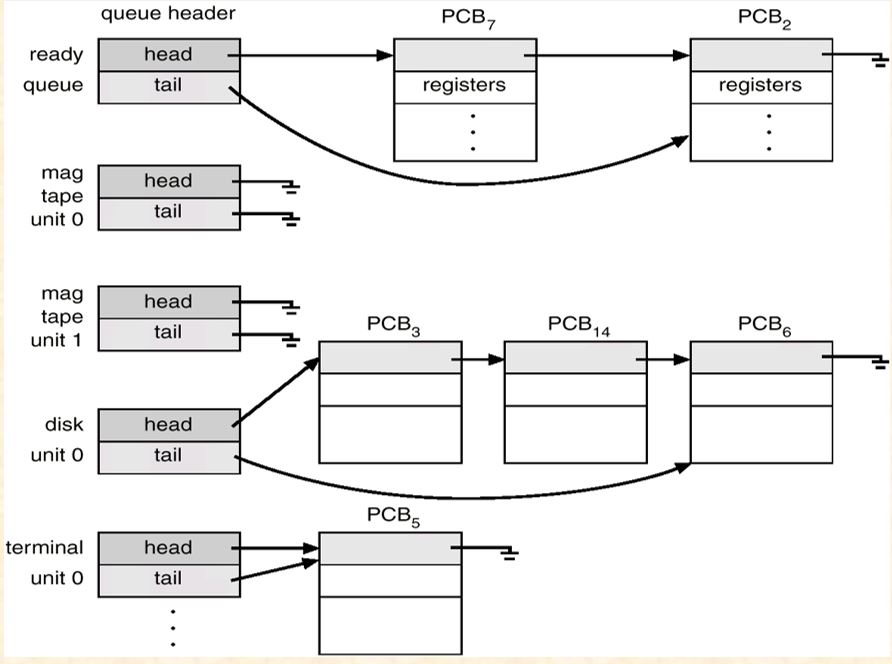
3.2.2 Schedulers
- Def:
- a software module in OS
- responsible for allocating resources (e.g. CPU, devices) among different processes
- Three types of scheduling
- short–term scheduling selecting which process should be executed next and allocates CPU, that is, selecting a process in ready state and running this process on CPU.
short-term scheduler is invoked very frequently.
- long–term scheduling selects process from the pool and loads them into memory for execution.
long-term scheduler is invoked very infrequently pool: Many processes are spooled to a mass-storage device, where they are kept for later execution.
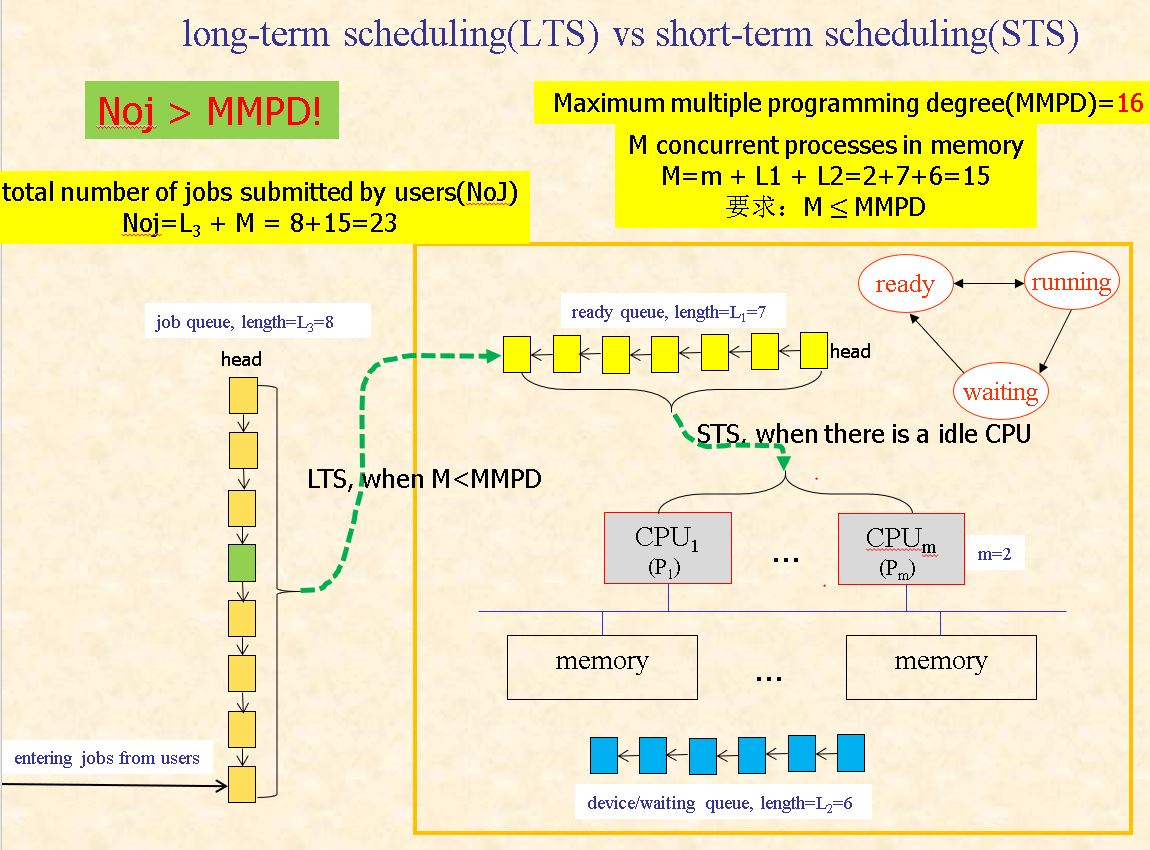
图的说明:MMPD类似Degree of multiprogramming,左边是LTS,其中一共分配了23个jobs,放在jobs queue中的有8个;剩下都在STS中分配:7个在ready queue等待CPU调度(ready),6个在device/waiting queue等待I/O操作(waiting),而m=2个CPU正在处理jobs(running),加起来15个。
补充:A process can be described as either
- I/O-bound process – spends more time doing I/O than computations, many short CPU bursts, or
- CPU-bound process – spends more time doing computations; few very long CPU bursts
It’s important that the long-term scheduler select a good process mix of I/O bound and CPU-bound processes.
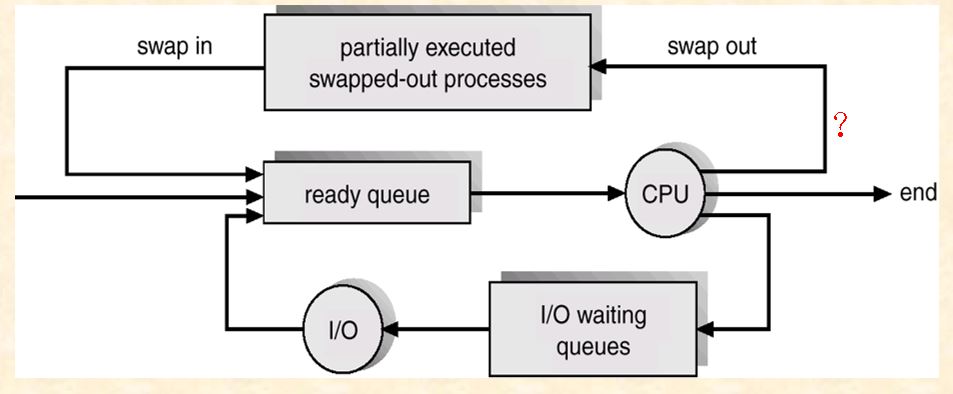
- medium–term scheduling
to control the degree of multiprogramming, guaranteeing the resources (such as main memory) demanded by all processes in memory has not overcommitted available resources.
- swapping out
- to reduce degree of multiprogramming and free memory or resources, removing processes in ready or running states from main memory and into swapping section on disks
- the process that is swapped out is delayed to execute
- swapping in
- reintroducing the processes on the disk into memory into memory, restarting their executing
- swapping out
3.2.3 Context Switch
When scheduler allocate CPU to a new process, the kernel saves the context of the old process in PCB, and loads the saved context of the new process scheduled to run.
Context-switch time is overhead!!! the system does no useful work while switching.
3.3 Operations on Processes
3.3.1 Process Creation
- Def: OS and other processes use creation primitive /system call to create a new process
- Creation Step:
- load the program code into main memory allocated to this process
- allocate resources (memory, I/O devices, files) to the process
- build the PCB for this process
- insert the PCB into ready queue, (and the process change into ready state)
Notice: The process being created is in ==new== state
 3. 父进程与子进程
3. 父进程与子进程
- 问题1:子进程资源分配问题
- child process obtain resources directly from OS
- obtain resources from its parent, being constrained to a subset of the sources of its parent, such as in Linux
- 问题2:子进程的地址空间分配问题
- the child copy address space of its parent
- the child has its independent address space
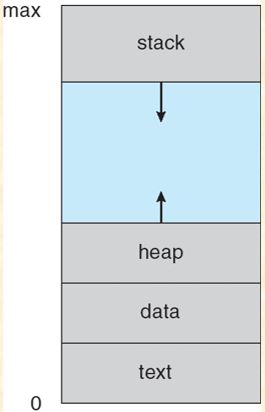
进程的地址空间构成: - 进程代码段 (text section) - 数据段 ( data segment) - 调用参数区与环境区的起始地址 - $\dots$
问题3:子进程如何执行
- parent and children execute concurrently
- parent waits until children terminate
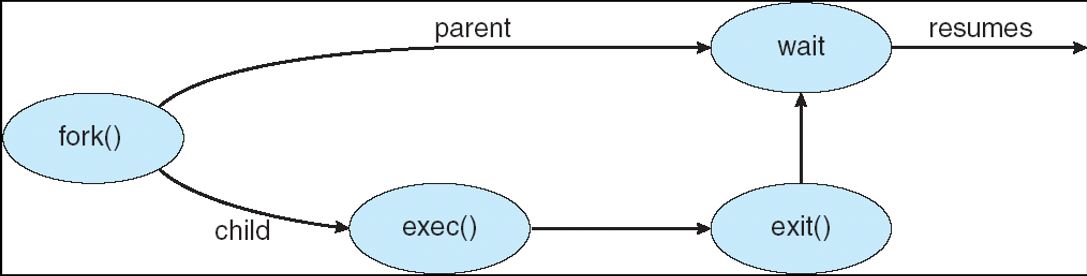
fork(): A new process is created by the fork() system call. Both processes(the parent and the child) continue execution at the instruction after the fork(), with one difference: The return code for the fork() is 0 for the new(child) process, whereas the nonzero pid of the child is returned to the parent. 子进程执行fork()以后的代码。
exec(): 利用exec原语,将子进程的自身代码加载到父进程的代码段中。
3.3.2 Process Termination
- Def: OS and parent processes can use the termination primitive/ system call (e.g. exit( ) in Linux ) to terminate a child process.
- Termination Step:
- output data from child to parent (via wait).
- child’s resources(e.g. devices) are de-allocated by the operating system
- release main memory allocated to the child
- remove the child’s PCB from ready queue or other queues
Notice: The process being terminated is in ==terminated== state
- abort():
- the child has exceeded its usage of some of allocated resources.
- tasks assigned to child is no longer required.
- the parent is exiting, so the child should also exit
- operating system does not allow child to continue after its parent terminates.
- cascading(串级,级联) termination.
- exit(): Terminate a process.
- wait(): Parent process may wait for the termination of a child process. It returns the pid of a terminated child so that the parent could tell which of its possibly many children has terminated.
3.4 Interprocess Communication (IPC)
A process runs concurrently with others, it may be
- independent process, which cannot affect or be affected by the execution of another process, e.g. idle
- cooperating process, which can affect or be affected by the execution of another process
Producer-Consumer Problem
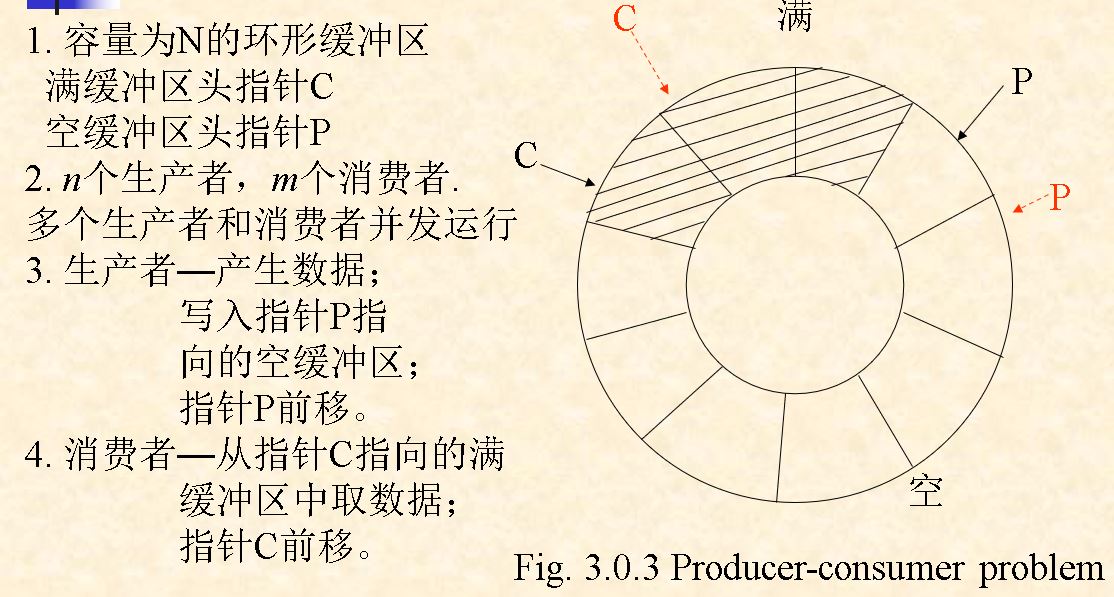 协同要求: .
协同要求: .
- 生产者写数据时有空缓冲块,如果不满足,则阻塞。
- 2个生产者不能同时向同一 空缓冲块写数据
- 消费者取数据时,有满缓冲块,如果不满足,则阻塞。
- 2个消费者不能同时从同一 满缓冲块取数据
- 生产者和消费者不能同时对同一缓冲块进行读写操作
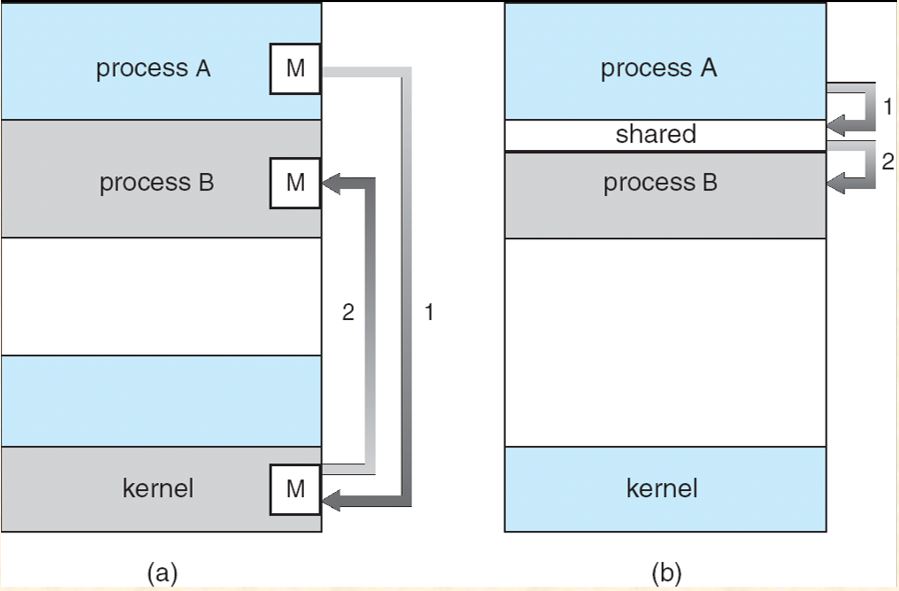
3.4.1 Shared-Memory System
The processes communicate with each others, by means of a region of shared memory. 用到的主要技术为==Producer-Consumer Model==。
(b) in the figure is Shared-Memory System.
- The unbounded buffer places no practical limit on the size of the buffer. The consumer may have to wait for new items, but the producer can always produce new items.
- The bounded buffer assumes a fixed buffer size. In this case, the consumer must wait if the buffer is empty, and the producer must wait if the buffer is full.
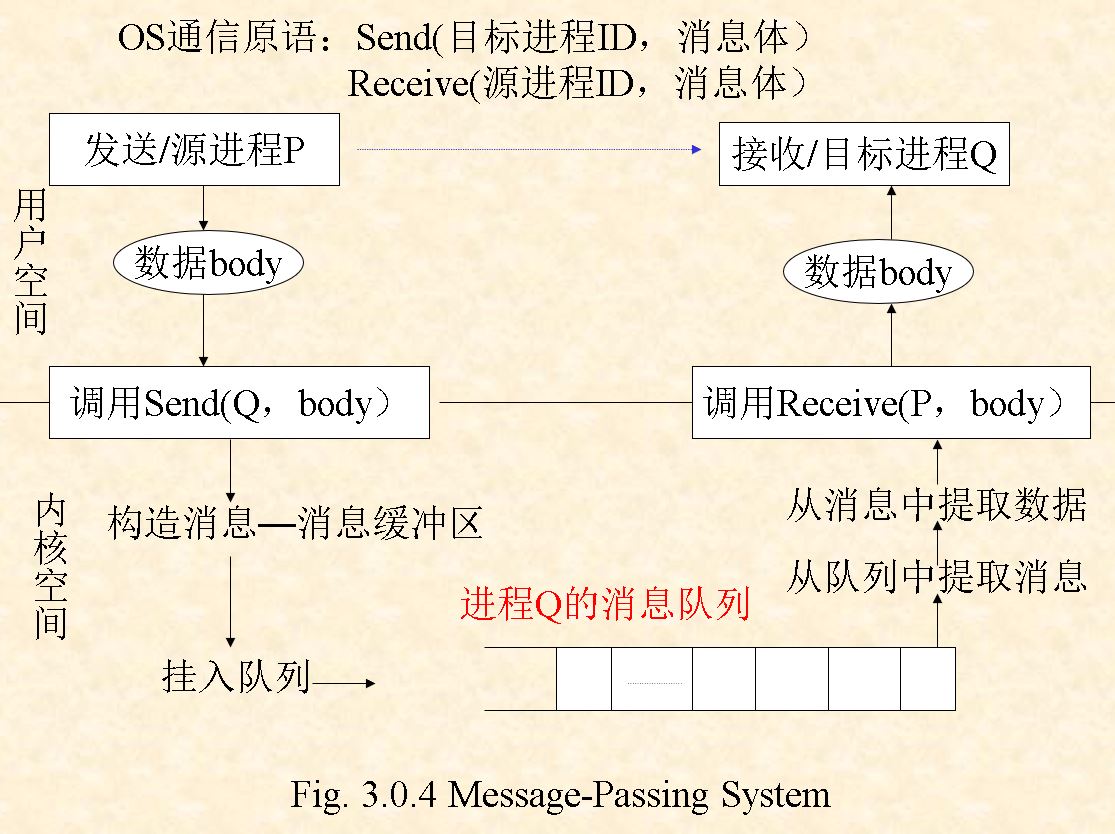
3.4.2 Message-Passing Systems
A IPC mechanism provided by OS, i.e. implemented in kernel space, via system calls, such as send and receive (a) in the figure is Message-Passing Systems.
- Naming
Direct Communication For sender process P and receiver process Q, they must explicitly name each other, using two system calls.
- send (Q, message) – send a message to process Q
- receive(P, message) – receive a message from process P
 Properties of communication link
Properties of communication link - links are established automatically.
- a link (e.g.队列) is associated with exactly one pair of communicating processes.
- between each pair of processes there exists exactly one link.
- the link may be unidirectional, but is usually bi-directional.

Indirect Communication messages are directed and received from mailboxes (or ports) in kernel space.
- each mailbox has a unique id.
- processes can communicate via send and receive only if they share a mailbox.
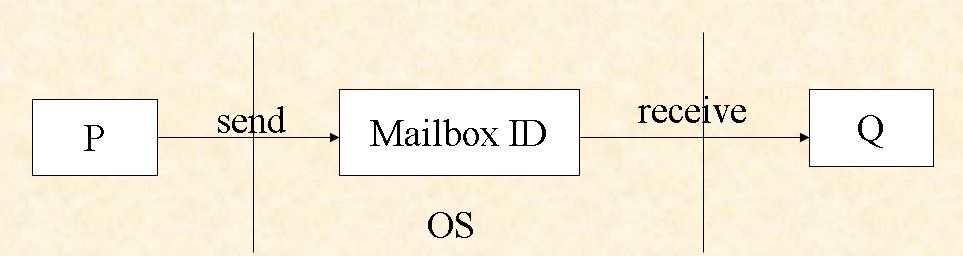 Properties of communication link
Properties of communication link - the link is established only if processes share a common mailbox
- a link (Mailbox) may be associated with many processes, i.e., ==a mailbox is not specific to a particular pair of processes.==
- each pair of processes may share several communication links.
- links may be unidirectional or bi-directional.
- Synchronization
- Blocking send: The sending process is blocked until the message is received by the receiving process or by the mailbox.
- Nonblocking send: The sending process sends the message and resumes operation.
- Blocking receive: The receiver blocks until a message is available.
- Nonblocking receive: The receiver retrieves either a valid message or a null.
- Buffering
- zero capacity
- bounded capacity
- unbounded capacity
3.6 Client-Server Communication
- Sockets(知道)
- Remote Procedure Call(RPC) (掌握)
Benefits
- a way to abstract procedure calls mechanism for use in network environments
- independent on OS
- for the purpose of IPC, more convenient than I/O operations or message-passing system
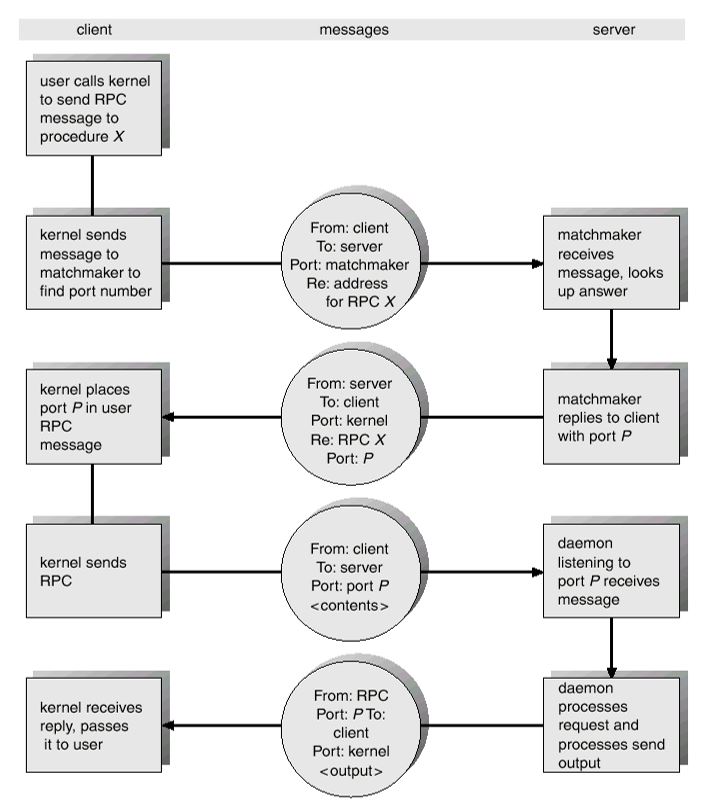
Some concepts:
- Stubs (存根)
- client-side proxy for the actual procedure on the server,locates the server and marshalls the parameters.
- server-side stub receives this message, unpacks the marshalled parameters, and performs the procedure on the server
- Binding (联编) in procedure call
- replace the called procedure’s name with the memory address of this procedure
- Binding in RPC
- how to locate the called procedure in server, i.e. for client how to know the port number of the called procedure
- Stubs (存根)
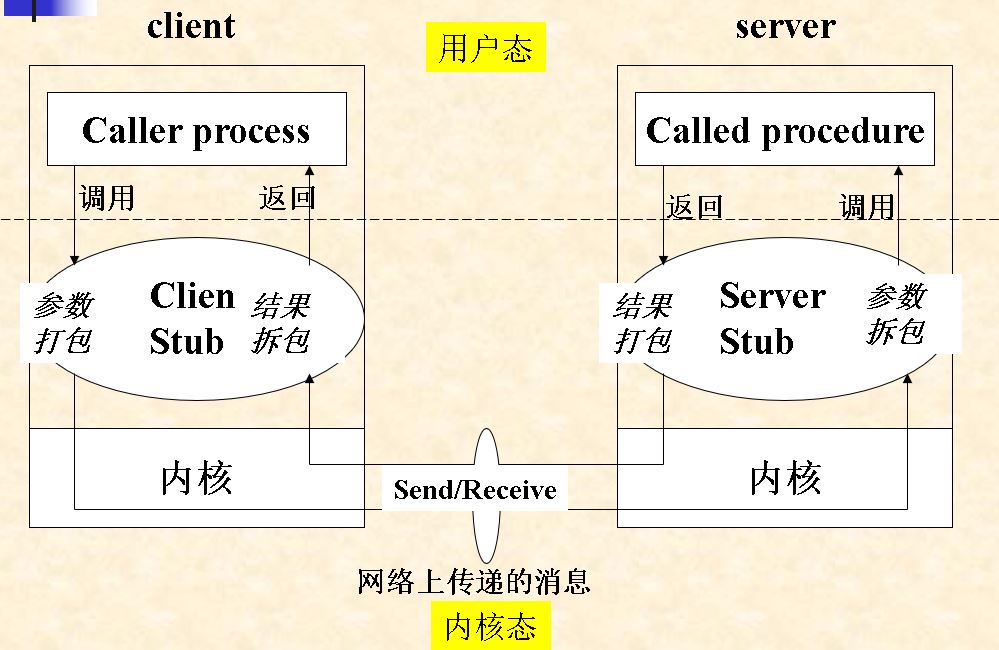
1.客户程序(caller process)按通常的(类似于本地的)调用方式,调用客户存根 2.客户存根创建一个消息,封装参数,并陷入内核 3.内核将该消息发送给服务器端内核 4.服务器端内核将该消息传递给服务器存根 5.服务器存根从消息中获取参数,并调用服务器程序(called process) 6.服务器程序完成工作,将结果返回给服务器存根 7.服务器存根将结果打包进消息,并陷入OS内核。 8.服务器内核将消息返回给客户端内核 9.客户端内核将消息传递给客户存根 10.客户存根取出结果,返回给客户端调用程序
- Remote Method Invocation(了解)
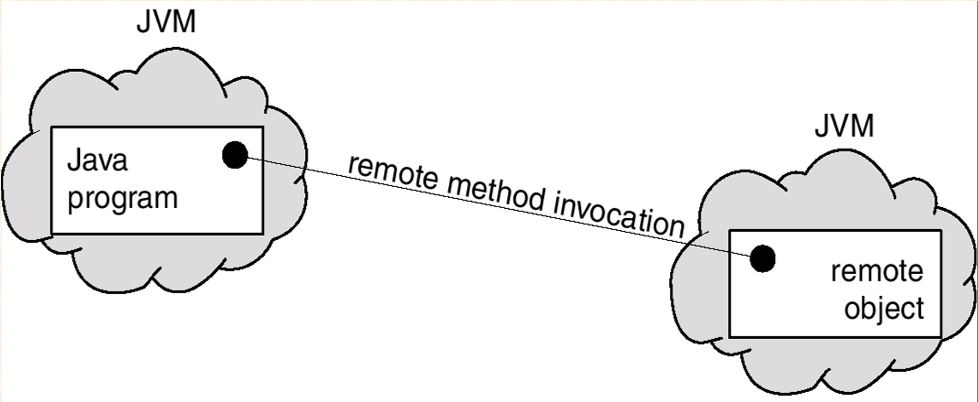
Chapter 4 Threads
4.1 Overview
引入线程的原因:提高CPU资源利用率
- 减少内核态下的CPU switch的时间,降低管理成本
- 快速启动程序(分配资源、创建线程)
进程的上下文切换示意图
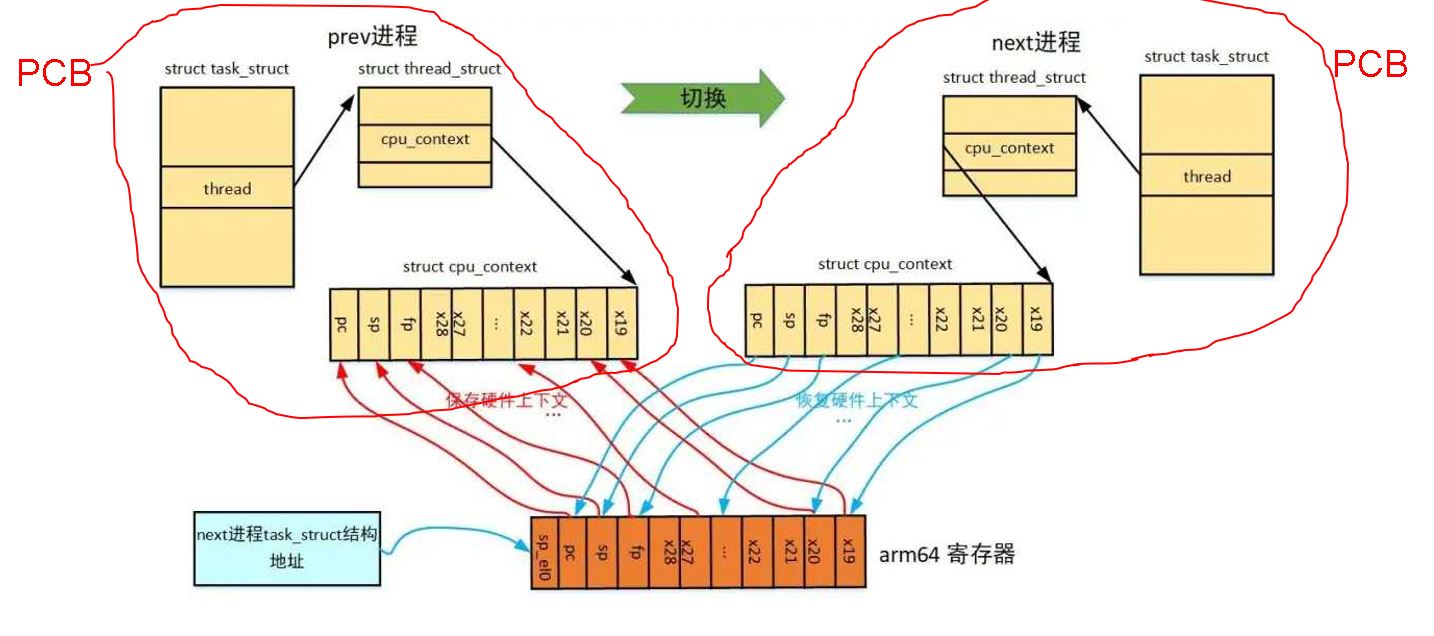 进程的上下文切换开销包括
进程的上下文切换开销包括
- 直接开销
- 间接开销:==进程切换后局部性失效==
进程是资源调度的单元,线程是CPU调度单元和运行实体。
- 给线程分配CPU资源,并共享进程资源
- 切换、创建开销小
- 提高并行性
更为直观的表示进程切换和线程切换的时间开销对比
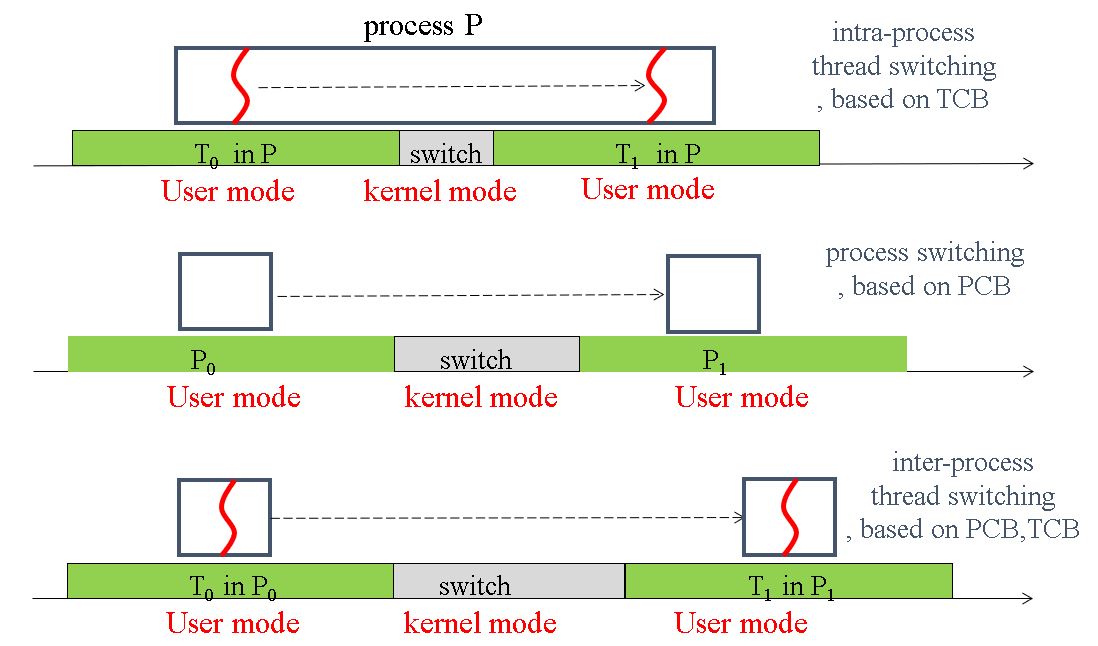
最后为不同进程的线程切换,时间开销最大
协程:用户级线程
- 与内核级线程的对比:协程创建的内存开销远小于内核级线程的内存开销。
注意:一个进程可以对应多个线程 thread = thread ID + program counter + a register set + stack heavyweight process => 进程 lightweight process => 线程
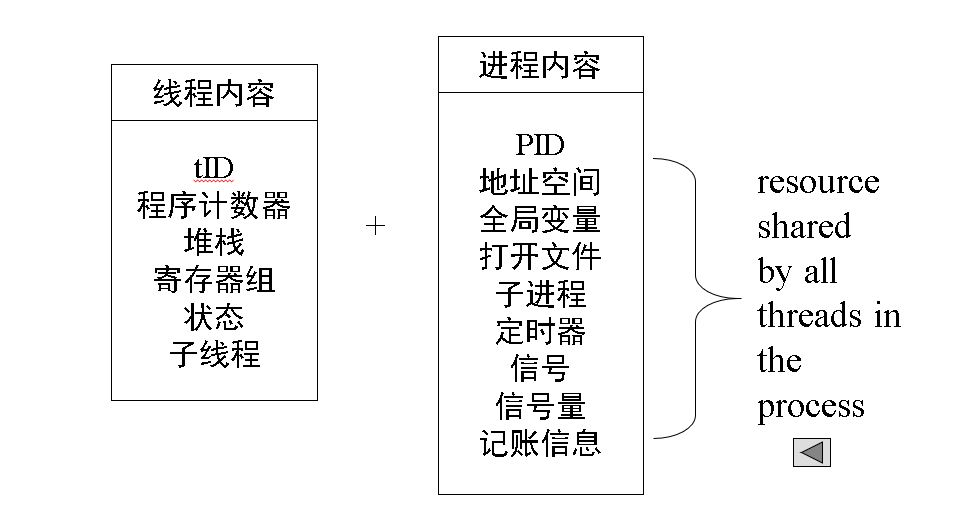 进程内容为线程的共享内容。对于每一个线程有独立的寄存器和栈空间。
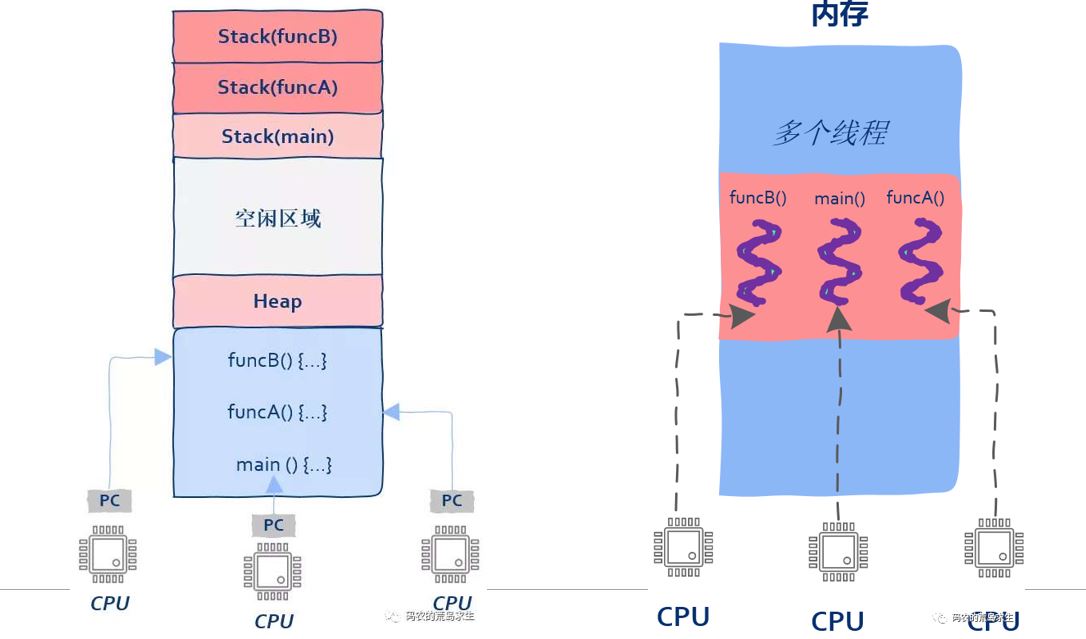
多线程内存占用及执行轨迹
进程内容为线程的共享内容。对于每一个线程有独立的寄存器和栈空间。
多线程内存占用及执行轨迹
4.2 Multithreading Models
- User-level threads(ULT) e.g Coroutine(协程). Thread management (creating, scheduling,..) is conducted by the user-level threads library, or by programming environments.
例如 pthread 用户级线程库
- Kernel-level threads(KLT) OS is responsible for creating and managing TCB
核心问题:For the ULT, how to occupy the CPU?
- mapping between user threads and kernel threads
- mapping is conducted by the compilers
3.Thread Scheduling Two-level scheduling for ULT
- local scheduling how the threads library decides which thread to put onto an available LWP
- global scheduling how the kernel decides which kernel thread to run next
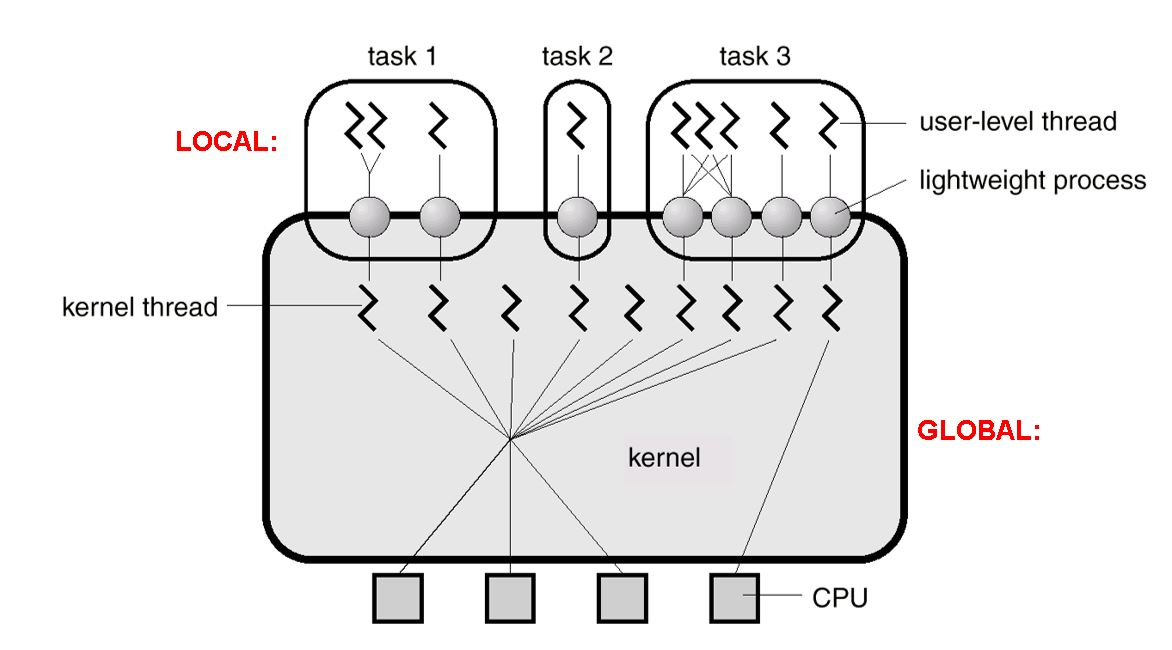
- ULT-to-KLT Mapping
此处PPT中有3个实例图,切记Linux没有标准线程的概念
- Many-to-one 获得CPU概率最小,并行性最低
- One-to-one 获得CPU概率最大,并行性最高,可以分配给重要线程,利用CPU绑定的方法
- Many-to-many 一般情况下是用户线程数大于内核线程数
4.3 Thread Libraries
A thread library provides the programmer an API for creating and managing thread.
- First approach, ULT: invoking a function in the library results in a local function call in user space
- Second approach, KLT: invoking a function in the API for the library results in a system call to the kernel
- Linux Thread ==Linux refers to them as tasks rather than threads.== Thread creation is done through clone() system call. clone() allows a child task to share the address space of the parent task (process)
完全在用户空间模拟对线程的支持
4.4 Threads Issues
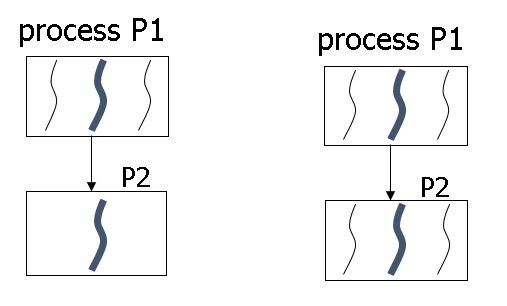
Thread Creation If one thread in the parent process P1 calls fork to create a new child process P2, the new process P2 will
Thread cancellation
- asynchronous cancellation 立即停止当前线程
- deferred cancellation 等待子进程的结束后再结束进程
- Signal
- a facility provided by OS to notify a process that a particular event occurred.
- event-driven mechanism
事件驱动、软件驱动、由OS处理(类似软中断)
Two types of signal
- synchronous signals:由内部事件产生
- asynchronous signals:由外部事件产生
从User mode转到Kernel mode执行信号服务程序。
- Thread Pools
- a set of pre-created threads, the number of threads in this set is limited
- used to bound the number of threads concurrently active in the system
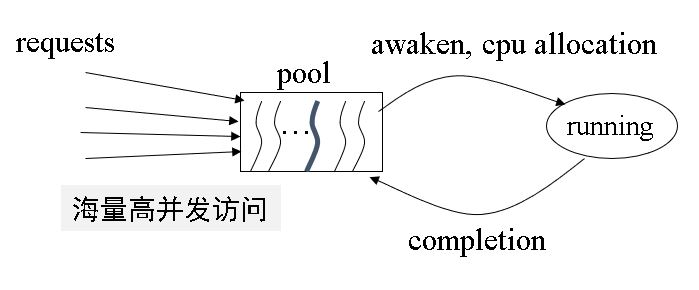
空闲态(收到request)$\rightarrow$激活态 激活态(收到complete)$\rightarrow$空闲态
Question:How to determine the number of threads in pool?
- 首先区分任务/进程类型:CPU-bound和I/O-bound。
- CPU计算时间记成CT,I/O计算时间记成WT
- M:线程池中线程数量M,后端服务器CPU核数N
根据以上条件,可以得出M的取值为
- CPU密集型任务:M = N
- I/O密集型任务:M = N*(1+WT/CT)
- Thread-specific data Data in thread includes
- shared data (进程块信息)
- Thread-specific data
4.5 线程的状态
3个基本进程状态:就绪、运行、等待/阻塞 与进程的区别:
- 无挂起状态,线程不是资源拥有者,无权决定从主存中撤出
- 进程内某个线程阻塞时,整个进程并不阻塞,进程内其它线程仍维持原各自状态,参与调度
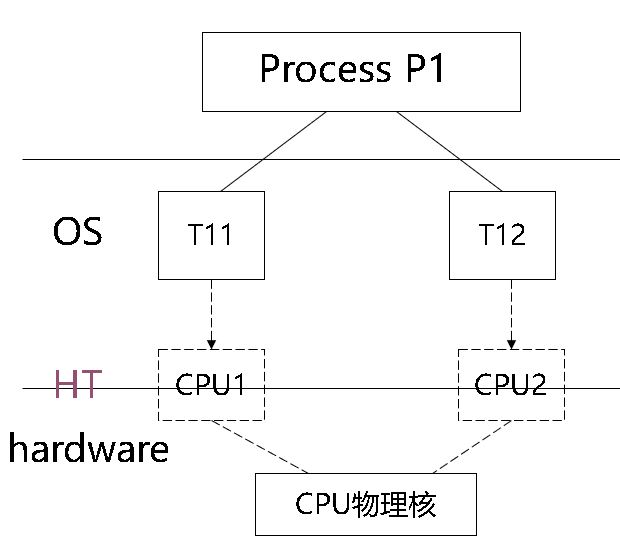
4.6 HT(超线程)技术
- Concept
- 在一个物理核上模拟两个逻辑核
- 两个逻辑核具有各自独立的寄存器(eax、ebx、ecx、msr等等)和APIC,但共享使用物理核的执行资源,包括执行引擎、L1/L2缓存、TLB和系统总线等
性能分析 HT通过物理核上的计算资源高效复用,提高了进程/线程的整体吞吐量。性能提高大约1.3倍。 有HT竞争时的计算时间:无HT竞争时的计算时间 = 1:0.65
超线程技术的图解:
4.7 多核CPU技术
双核CPU的优势:双核系统平均较单核系统快==60-70%==
多核/HT CPU速度提升 (1) 方法一:n核m线程(保守估计) 双核性能提升1.7倍 + HT性能提升1.3倍 $$SP=[1.7 \times (n/2)] \times 1.3$$ (2) 方法二:n核m线程(乐观估计) 不考虑双核算作单个逻辑核时性能上的减少,单考虑HT性能提升 $$SP=1.3\times n$$ (3) 方法三:n核n线程无HT 只考虑双核带来的性能降低 $$SP=(1.7-1.9)\times (n/2)$$ (4) 方法四:n核m线程(带HT,非线性乐观估计) 将2核4线程的$1.3\times1.7=2.21$作为一个整体代表双核 $$SP=[(1.7\times1.3)^{log_2n}]$$ (5) 方法五:n核n线程(无HT,非线性保守估计) 将2核2线程的$1.7$作为一个整体代表双核 $$SP=[(1.7)^{log_2n}]$$
CPU亲和力和CPU绑定
- 软亲和力:内核进程调度分配到原先的CPU,不会在处理器中间频繁切换;
- 硬亲和力:进程固定/==绑定==在某个处理器运行
分解的子问题数目越多,利用多个CPU/计算核同时并行求解的子问题越多,算法复杂性越低,程序运行速度越快!
- 并行算法加速比 同一个任务在单处理器系统和并行处理器系统中运行消耗的时间的比率 $$SP=T_1/T_p$$ 其中$T_1$:单处理器下的运行时间,$T_p$:有p个处理器并行系统中的运行时间
当SP=P时,称为线性加速比
- 阿姆达尔定律 在固定负载情况下,加速比SP: $$SP=\frac{1}{a+(1-a)/n}$$ 其中a:串行计算部分所占比例,n:并行处理节点个数。 极限加速比:当$n\rightarrow\infin$,$s\rightarrow1/a$