
Brandon Zhang
June 11, 2021
Transformer
I. Transformer Overview
Seq2seq model
Input: sequence of vector
Output: sequence (not fixed size)
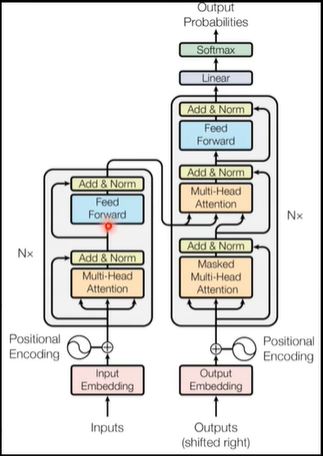
II. Encoder
It is actually a Self-Attention Model!
对于一个block,它的结构可以理解为以下的形式:
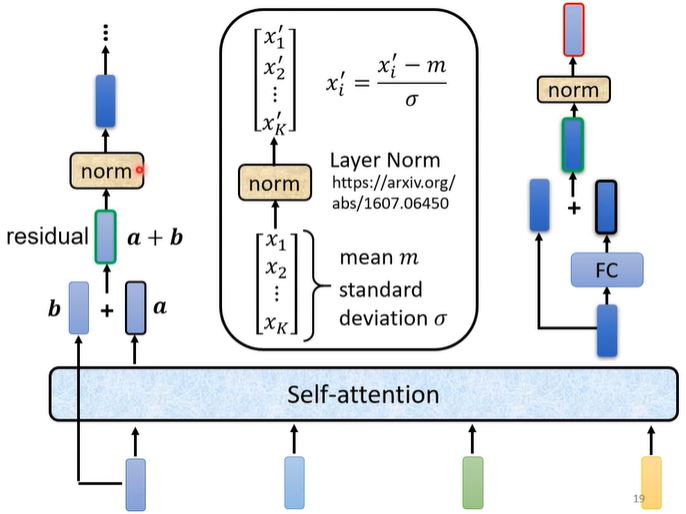
- 与self-attention不同的是,会采用residual add的方式,将self-attention得到的中间结果$a$加上输出$b$
- 经过layer normalization得到新的输出
- 将新的output输入到FC中,并加上residual
- 再次经过layer normalization得到这一个block的结果。
理解了一个block以后,整个Encoder就是由n个这种block组成的network。
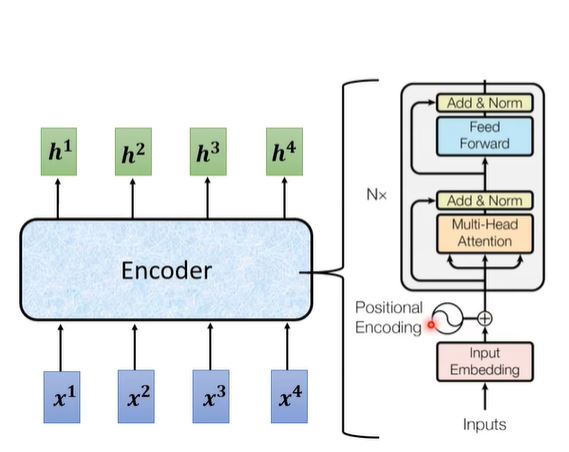
- 首先将word进行self-attention得到word embeddding,并在其中加入positional encoding信息
- 经过multi-head Attention或者Feed Forward Network后,都要接上residual + layer normalization,而这种设计结构就是Transformer Encoder的创新点所在。
III. Decoder —— Autoregressive(AT)
The model structure of Decoder is shown as follow:
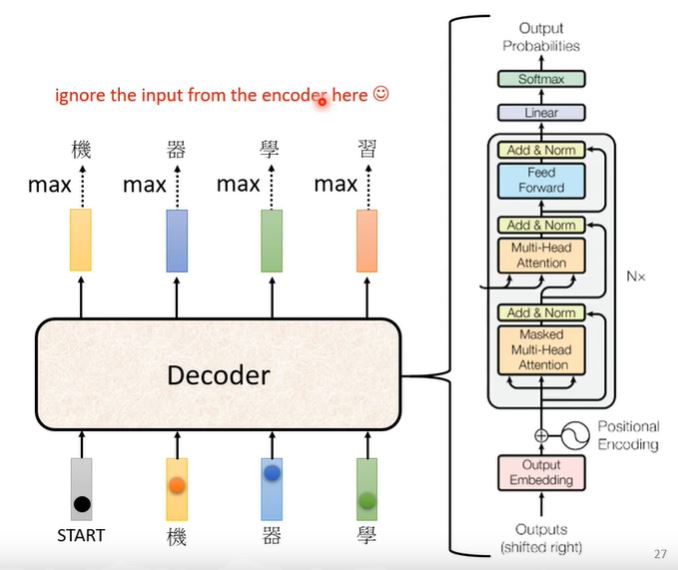
根据上图我们将逐步逐层地解释结构:
- Masked Multi-head Self-attention 在产生每一个$b^i$ vector时,不能再看后面的信息,只能和前面的输入进行关系:
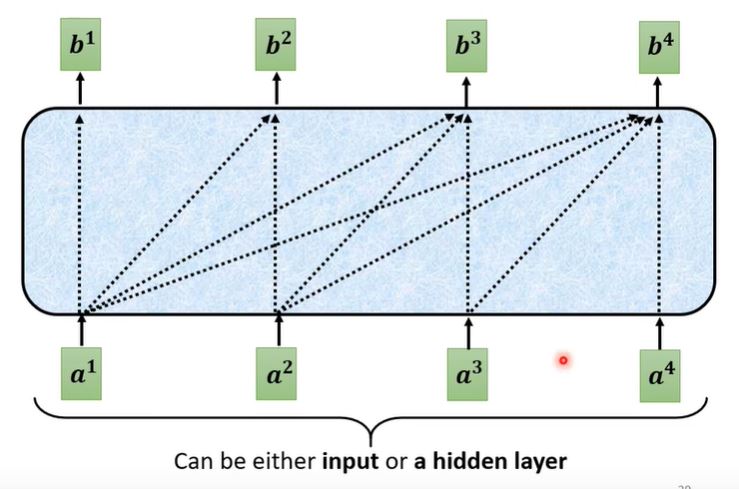
从细节上来看,要想得出$b^2$,我们只需将其和$k^1, k^2$做dot-product。
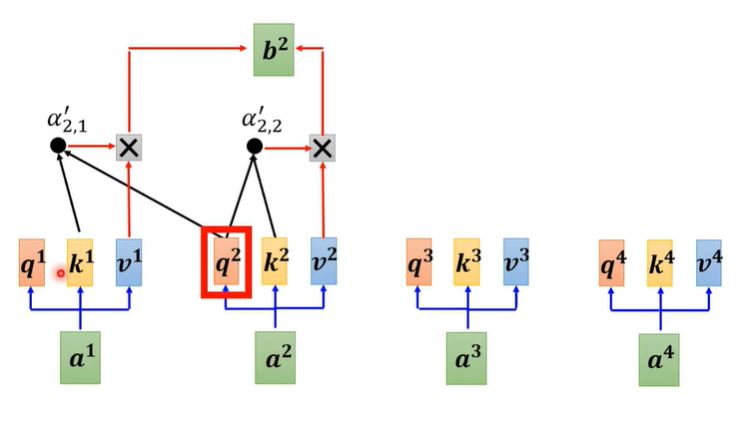
这么做的原因在于对于Decoder,它每一次的输入是来自上一次的输出,所以模型不存在右边输入,意味者self-atttention只能去考虑当前计算输出左边的输入做关联。
而对于Decoder而言,需要模型自己判断什么时候结束输出,得到not fixed sequence。我们需要对于输出的vector中添加新的一个维度[END],表示输出的结束,然后将这个输出的vector经过softmax得到概率最大的字符,若是END则输出结束。
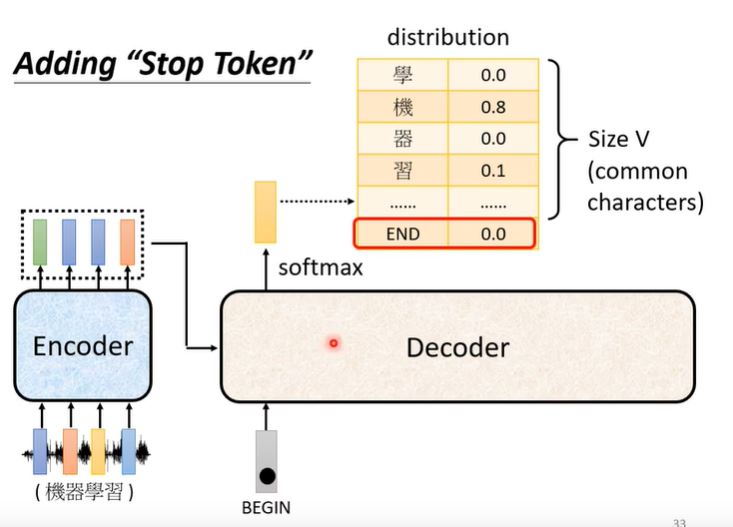
IV. Decoder —— Non Autoregressive(NAT)
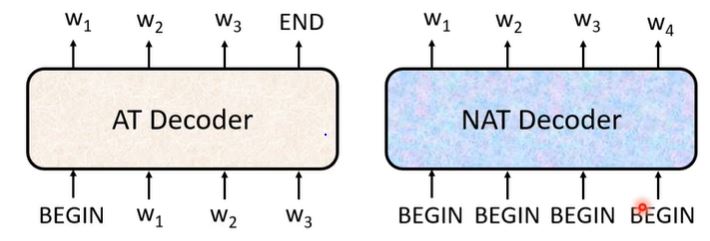
How to decide the output length for NAT decoder?
- Another predictor for output length
- Classifier: Encoder input $\rightarrow$ output length
- Output a veryh long sequence, ignore tokens after END
Advantage: parallel, controllable output length.
NAT: usually worse than AT
- reason: multi-modality
Encoder-Decoder
![]()
两者的连接最重要的就是Cross Attention,其工作原理如下所示:
- Encoder:提供$k, v$,两个输入
- Decoder:提供$q$,一个输入
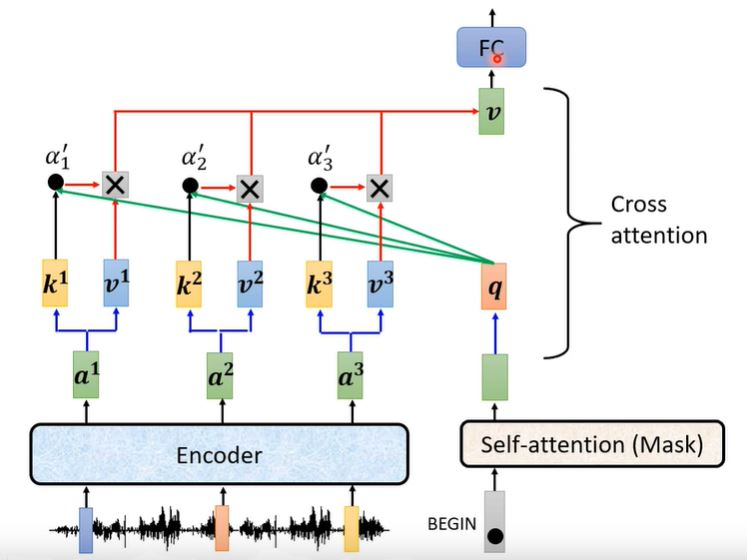
其实Decoder的每一层cross attention不一定要看encoder的最后一层输出,也可以看中间层的输出。对于cross attention的连接方式是各式各样的,可以作为一个sutdy进行研究。
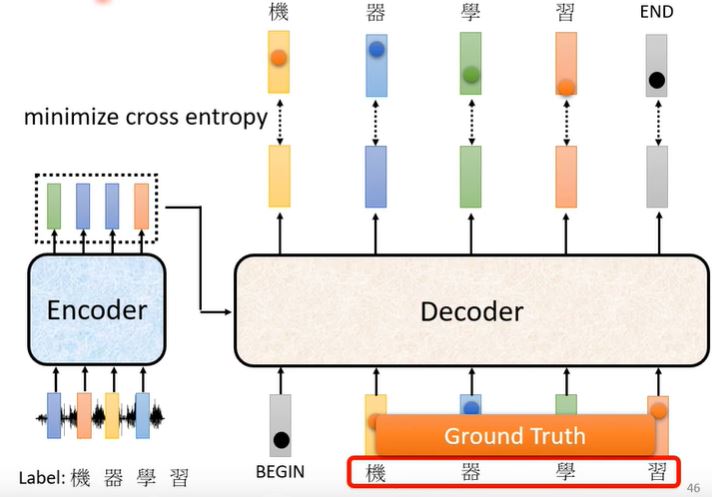
Training
- Ground Truth: one-hot encoding.
- Prediction: Distribution of probability.
- We will minimize cross entropy between ground truth and prediction.
Teacher Forcing
using the ground truth as input. 在Decoder训练的时候,我们在输入的时给它正确的答案。
Exposure Bias
- 起因:由于Decoder会将自己的输出作为下一次的输入,所以如果一步错,就会步步错,Decoder不断得到错误的输入并训练出错误的输出。
- 解决方法:Scheduled Sampling
Testing
在Testing中是对整体的输出和Ground Truth句子之间计算BLEU score。但之所以不在training phase去将BLEU score作为误差是因为其不可微分,无法使用gradient descent。
这里李老师讲了一个口诀,如果遇到optimization无法解决的问题,使用RL硬train一发就对了hhhh,把无法微分的loss function当作是RL的Reward,把Decoder当作是Agent、
Tips
Copy Mechanism
对于一些专有词汇,如果像Decoder一样根据上文预测下一字会效果比较差,一般而言使用copy mechanism可以将专有词汇进行复制,在一些words后面直接进行输出,这样效果会好很多。
Guided Attention
对于语音识别,Attention scores的峰值应该从左向右,为了使得模型训练没有偏差,可以直接将该模式放入模型的训练当中
Monotonic Attention Location-aware attention
Beam Search
从解空间树中找到一个approximate solution,使得结果近似optimal。但这种启发式搜索有时有用,有时不管用。对于一些结果特定的任务,Beam Search会很有帮助,但对于需要有创造力的任务,比如续写后文,Beam Search就没有太大用处。