
Brandon Zhang
June 11, 2021
Self-attention
I. Self-attention Overview
- Input: A sequence of vectors (size not fixed)
- Output:
- Each vector has a label (POS tagging)
- The whole sequence has a label (sentiment analysis)
- Model decides the number of labels itself (seq2seq)
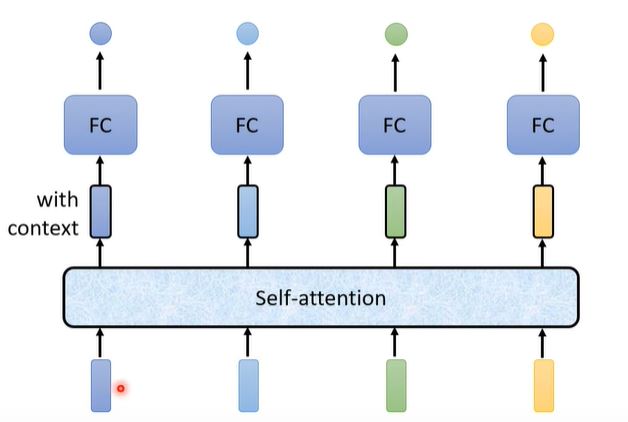
Self-attention can handle global iformation, and FC can handle local information. Self-attention is the key module of Transformer, which will be shared in other articles.
II. How to work?
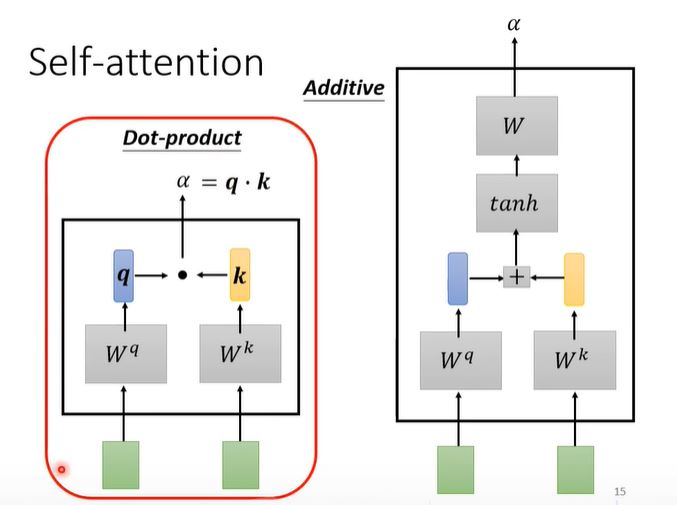
Firstly, we should figure out the relevance between each vector. Dot-product or Additive method is used to calculate relevant coefficient $\alpha$, also called attention score.
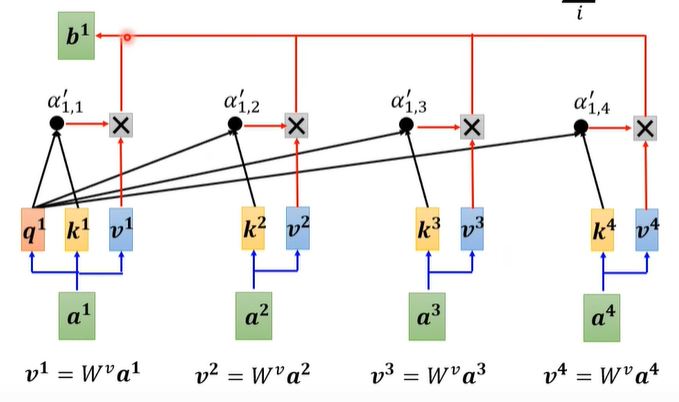
Then every vector $v$ multiply the attention score and sum them up, we could have:
$$
b^1 = \sum_{i} \alpha_{1,i}^{'} v^i
$$
从矩阵运算的视角可以再次去理解self-attention得到结果的过程:
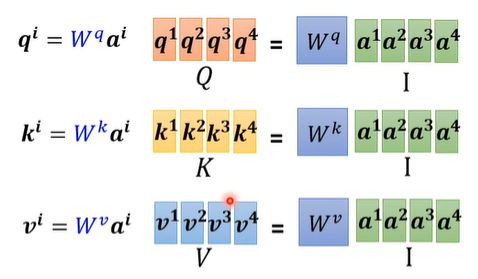
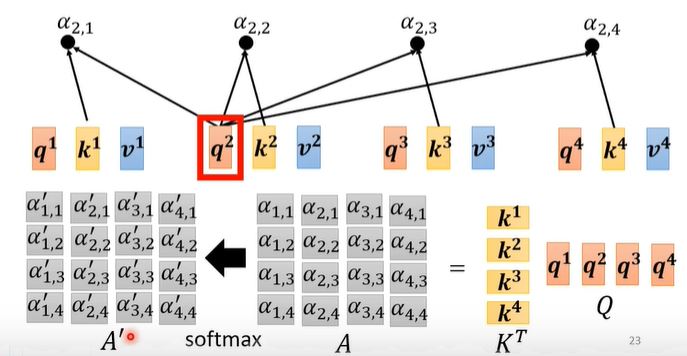
这里的softmax可以换成其他激活函数
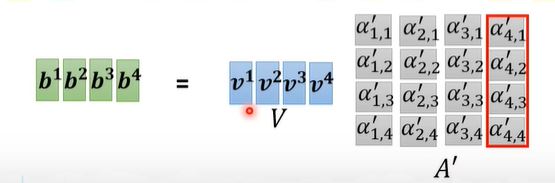
通过上述的运算可知,在一层self-attention layer当中,我们只需要学习$W^q, W^k, W^v$。
III. Multi-head Self-attention
与上述不同的是,需要在得到的$q, k, v$进一步乘以参数矩阵的得到更多的$q, k, v$,只有对应的$q, k, v$才可以进行dot-product和weighted-sum操作。
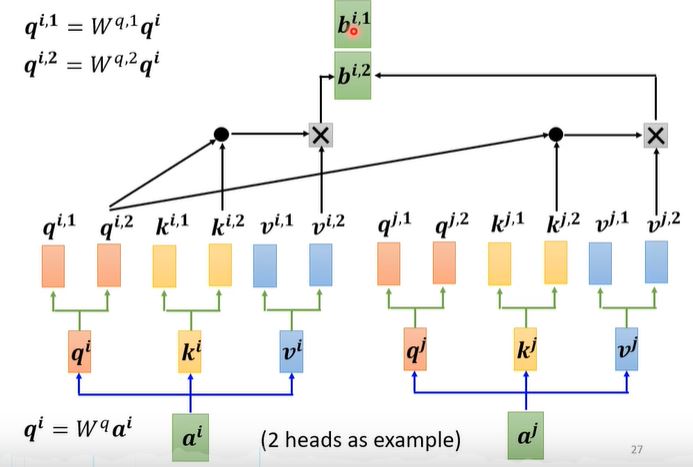
多少个head就会得到多少个vector $b$,接下来我们通过矩阵乘法得到最后的$b$传给下一层。 $$ b^i = W^o b^i $$
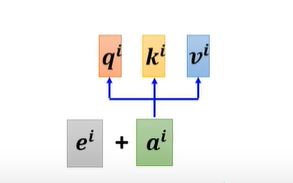
思考一下,可以发现No position information in self-attention,位置信息在这个机制中没有被考虑,所以为了加入位置信息,我们需要进行Positional Encoding。
Positional Encoding
- Each position has a unique positional vector $e^i$
- In 《Attention is all you need》, vector $e$ is hand-crafted
- BUT, it can also learn from data
Truncated self-attention
只看一部分范围,不和所有的$\alpha$进行运算。
IV. Self-attention vs CNN
CNN: self-attention that can only attends in a receptive field. (简化版的self-attention) Self-attention: CNN with learnable receptive field. (complex version of CNN)
《On the relationship between Self-Attention and Convolutional Layers》
V. Self-attention vs RNN
RNN: 两个相距较远的word 必须经过多个遗忘门,这种情况大大减少了两者之间的相关性。并且每一个hidden output是nonparallel输出的,有先后顺序。 Self-atttention:每一个word之间都会计算,所以位置因素不会影响。可以平行输出所有的output,训练效率更高。
《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention》
VI. Summary
现如今,广义的transformer就可以理解为Self-Attention,它现在有很多的变种,都会以*former来表示,而如何设计出good performance good efficiency的self-attention模型是现在的热点话题。
《Efficient Transformers: A Survey》