
Brandon Zhang
November 23, 2020
Database System Lecture Note 3
Chapter 10 Storage and File Structure
对于应用程序和disk而言,中间会有data buffer作为数据交换的缓冲池,替换算法一般采用LRU算法,注意两种可控的参数,在实验中会用到:
- 连接时长
- buffer大小
逻辑结构:
- 流式文件、基于记录文件、基于索引文件
物理结构:
- 以block为单位进行存储
- contiguous
- linked
- indexed
10.5 File Organization
Each file is a sequence of records, and a relational table is a set of tuples. A tuple is stored as a record in the DB file.
10.5.1 Fixed-Length Records
a block contains several records. Store record i starting from byte n * (i – 1), where n is the size of each record. 通过下标迅速定位record。 ==all records are stored in a contiguous space==
Free lists ==all records are stored in a noncontiguous space==
10.5.2 Variable-Length Records
- 定长在block的head,变长在block的tail(length、offset等)
- 通过bitmap记录NULL值
- <offset, length> 的定长元组放在前面

- Slotted Page
- 一个slot对应一个或多个record
- 将变长record存放在page之中
- Slotted Page header contains:
- number of record entries
- end of free space in the block
- location and size of each record
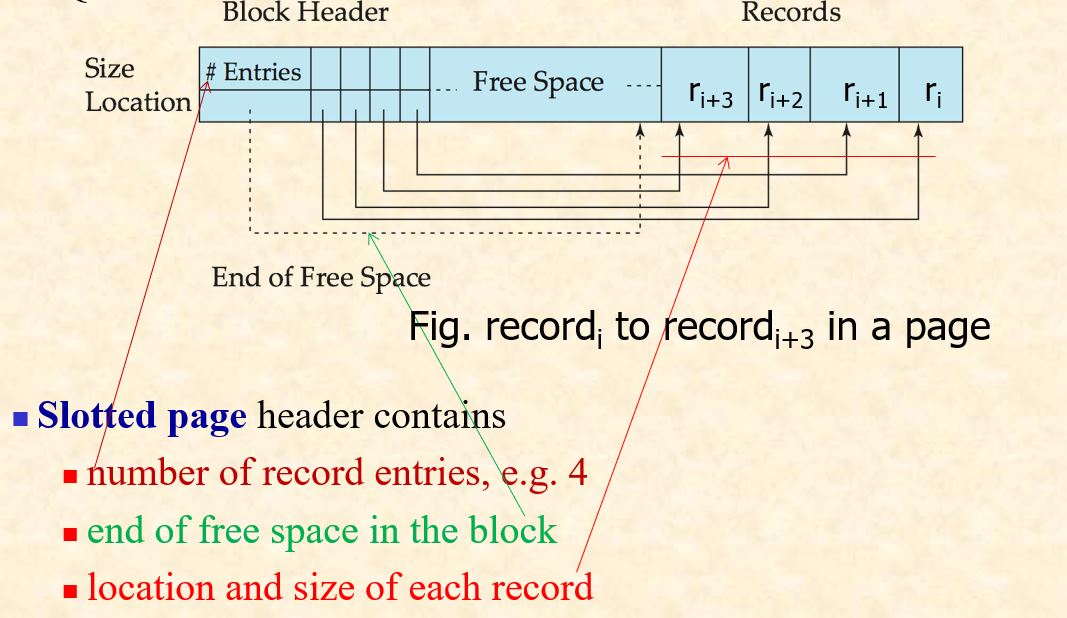
- delete and move
- the pointer to $r_i$ should point to the entry for the record in header
- 需要更改三个地方
10.6 Organization of Records in Files
- Heap 破坏逻辑顺序、但增删改很快。
- Typically, there is a single file for a relation
- 一般以纪录的输入顺序为序,决定了文件中记录顺序
- 纪录的存储顺序与记录中的主键无关 E.g. 创建新关系表student(ID, name, total-credits),但不在student上定义主键、候选键、各类索引,student被组织为heap file;通过insert,将记录/元组加到堆文件中。
- Sequential 加入索引后,查询很快,增删改变慢。
- Records are logically ordered by search-keys.
- Chain together records by pointers.
- Need to reorganize the file from time to time to restore sequential order.
- Hashing
- The file records are stored in a number of buckets, the #bucket is the address of the record

- Multitable Clustering File Organization motivation: store related records on the same block to minimize I/O.
- 这种方式对于包含join操作的查询很有好处,方便natural join
重点!: 索引对于
- select有正作用
- 增删改有负作用(若没有用到索引,则无作用)
- update需要分情况讨论,有些update操作既利用查询也用到改,这种正+负的作用最后往往是整体负效果。
10.7 Data Dictionary Storage
The Data dictionary (also called system catalog) stores metadata
- Information about relations
- names of relations
- names, types and lengths of attributes of each relation
- names and definitions of views
- integrity constraints
- User and accounting information, including passwords
- Statistical and descriptive data
- number of tuples in each relation
10.8 Buffer Management
 LRU算法替换
LRU算法替换
Appendix
I.
在一些小型关系数据库系统(dbase, Foxbase)
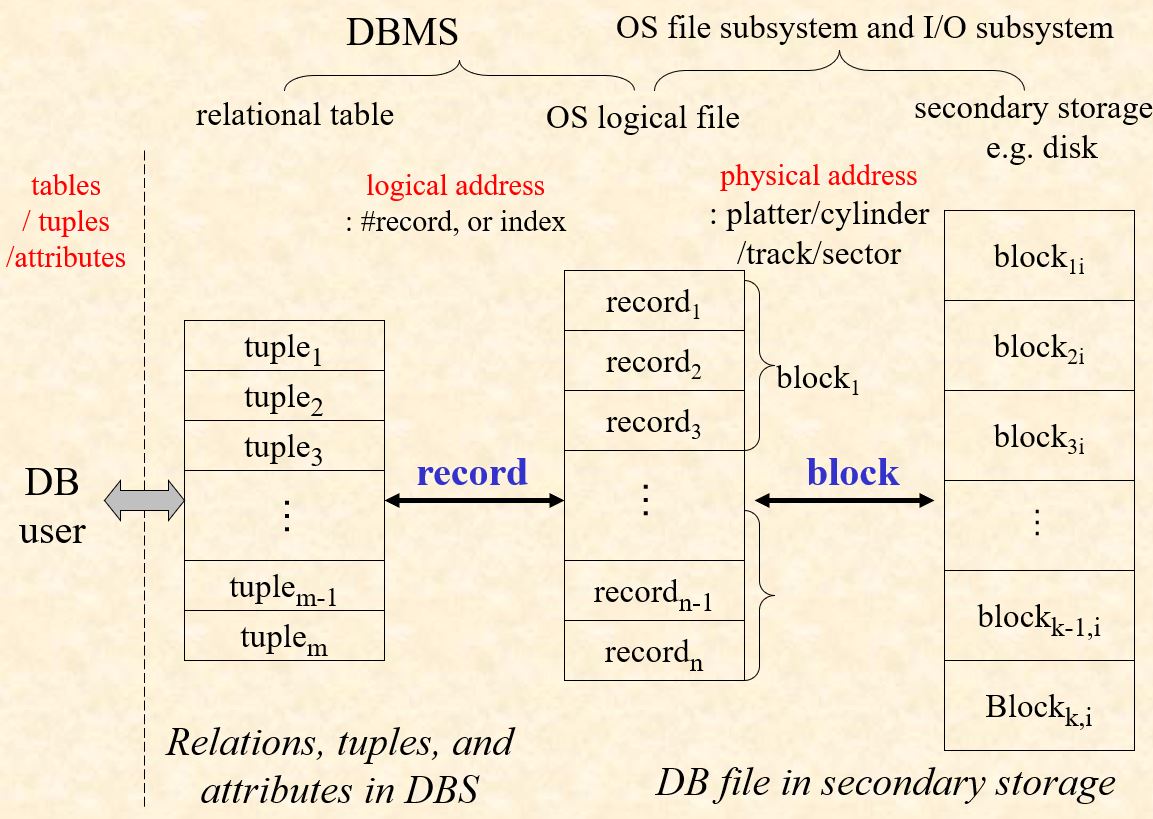
- DB关系表中元组/数据行 到 DB文件中数据的逻辑地址(文件名,记录号)间的映射
- DB文件记录号到外设上数据物理地址(记录所在的物理块号和具体地址)的映射
II.
在一些大型关系数据库系统(SQL Server, Oracle)
SQL Server利用索引分配映象IAM数据结构纪录每个数据库文件的页与该页所在物理盘区间的对应关系

Chapter 11 Indexing and Hashing
11.1 Basic Concepts
Search Key attributes or a set of attributes used to look up the records in a file
Indexing mapping from search-key to storage locations of the file records
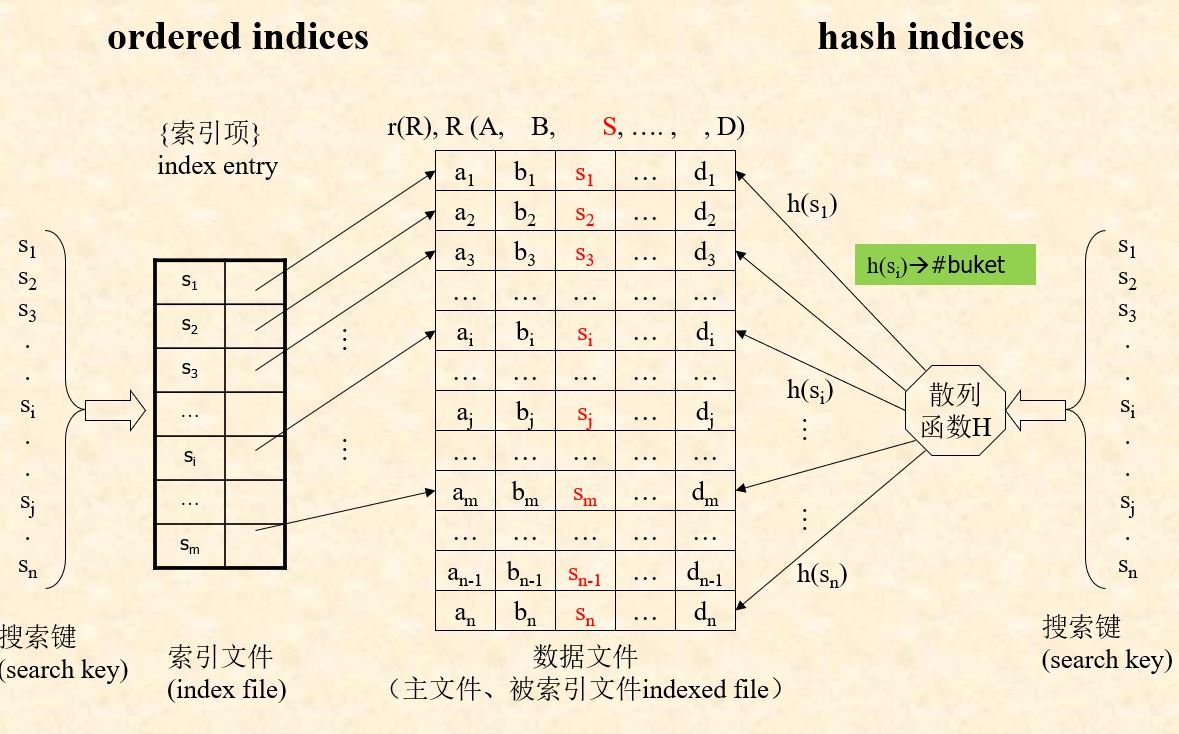
- ordered indices: the index file is used to store the index entries in which the search key of the records and the address of the records are stored in sorted order
- hash indices: the “hash function” is used to map the the search key of the records to the address of the records. The records are stored in the “buckets”
索引支持等值、比较、范围查询
11.2 Ordered Indices
DB files with indexing mechanism include 2 parts:
- indexed file: in which data records are stored;
- index file: in which index entries are included.
In index file, the index entries in the index file are stored in accordance with the order of the search key.
11.2.1 Primary and Secondary Indices
- Primary Index (Clustering Index) 索引文件的搜索键所规定的顺序和被索引的顺序文件中的记录顺序一致。
聚集索引 vs 主索引 主索引:建立在主键的索引。 一张表只能一个聚集索引,因为数据文件根据索引项进行排序,只能有一种排序顺序。但可以建立多个非聚集索引。 主索引一定是聚集索引,聚集索引不一定是主索引。
- Secondary Index (non-clustering Index)
Def: an index whose search key specifies an order different from the sequential order of the file.
Secondary indices have to be dense indices.
Dense index: the index record in the index file appears for every search-key value in the indexed file.
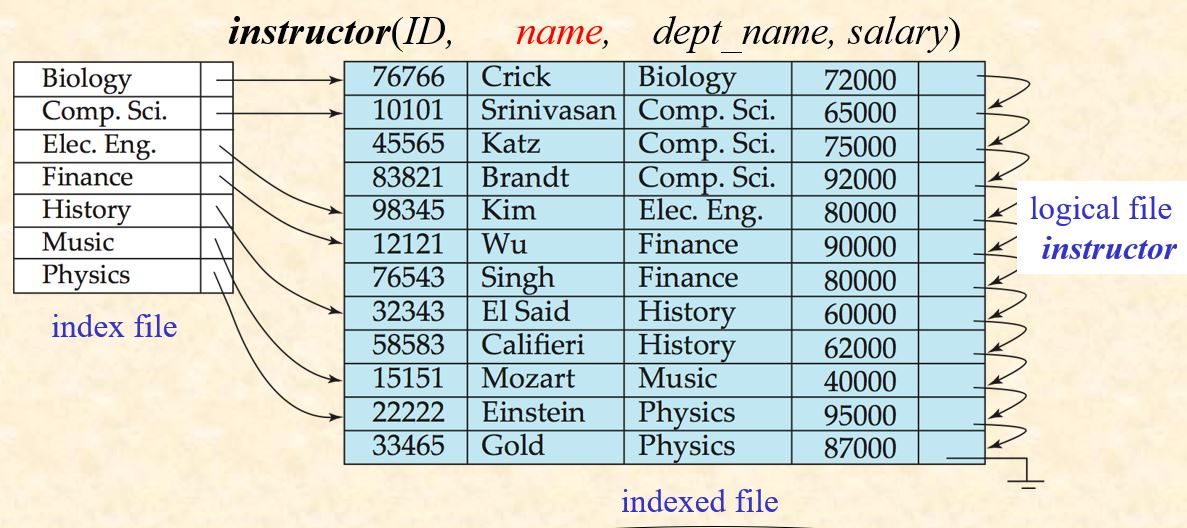
Sparse Index: index file contains index entries for only some search-key values in the indexed file
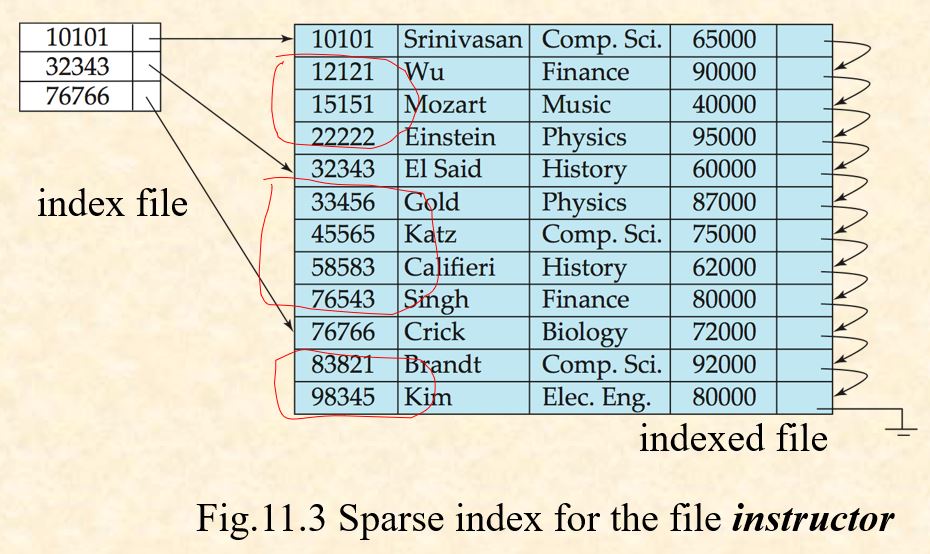
- Primary vs Secondary Indices Sequential scan using primary index is efficient, but a sequential scan using a secondary index is expensive.
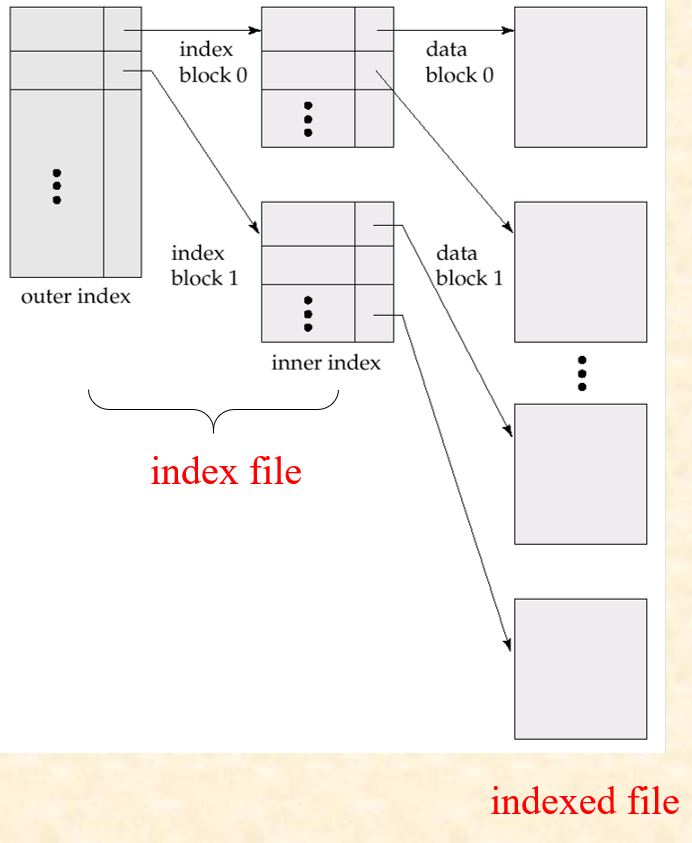
11.2.2 Multi-level Indices
Sometimes the index file may be very large, and cannot be entirely kept in memory. Solution: treat primary index kept on disk as a sequential file and construct a sparse index on it.
- outer index: a sparse index of primary index file
- inner index: the primary index file
11.2.5 Indices on multiple keys
Composite search keys are search keys containing more than one attribute. E.g. (dept_name, salary) E.g. create index Mutiple-index on takes(course_id, semester, year)
左前缀原则:


三个重要概念: table scan: 表组织为堆文件,依次扫描判断满不满足where查询条件。 index seek: 用索引寻找(从上至下),对应聚集索引的查找,效率较高。 index scan: 不用索引寻找,对应利用聚集索引建起来的树进行非聚集索引的查找,在索引顺序文件的叶子结点从左向右遍历。
11.3/11.4 B+树 / B树
此处考试不做要求,但对于数据库而言是很重要的组织索引的数据结构,一定要理解!
- Primary index 文件记录直接存储在叶节点
- Secondary index 叶节点存储指向文件记录的指针
11.5/11.6 Hashing Index Files
- Hash Indices
Hashing can be used not only for file organization, but also for index-structure creation.
A hash index organizes the search keys, with their associated record pointers, into a hash file structure.
Hash indices are always secondary indices
Static hashing hash function h cannot be modified, while being used
Dynamic hashing hash function h to be modified dynamically
11.8 Comparison of Ordered Indexing and Hashing
- 等值查询:Hashing
- 范围查询:Ordered Indexing
11.10 Index Definition and Usage in SQL

ATTENTION 使用索引不一定真的能提高select查询速度。 对于非聚集索引的查找对比直接扫描数据文件,可能后者更快!