
Brandon Zhang
October 27, 2020
Syntax-directed Translation
语法制导翻译技术
整体思路:
- 首先,根据翻译目标来确定每个产生式的语义;
- 其次,根据产生式的含义,分析每个符号的语义;
- 再次,把这些语义以属性的形式附加到相应的文法符号上(即把语义和语言结构联系起来);
- 然后,根据产生式的语义给出符号属性的求值规则 (即语义规则),从而形成语法制导定义。
==翻译目标决定产生式的含义、决定文法符号应该具有的属性,也决定了产生式的语义规则。==
两种描述语法制导翻译的形式:
- 语法制导定义:是对翻译的高层次说明,它隐蔽了一些实现细节,无须指明翻译时语义规则的计算次序
 L-属性可以一遍扫描,省去分析树和依赖图的步骤。
L-属性可以一遍扫描,省去分析树和依赖图的步骤。 - 翻译方案:指明了语义规则的计算次序,规定了语义动作的执行时机。
5.1 语法制导定义以及翻译方案
5.1.1 语法制导定义
对上下文无关文法的推广
综合属性 左部符号的综合属性是从该产生式右部文法符号的属性值计算出来的;在分析树中,一个内部结点的综合属性是从其子结点的属性值计算出来的。 在分析树中,若一个结点的某一属性由其子节点属性决定,则为综合属性 若在一个语法制导定义仅仅使用综合属性,则称之为S-属性定义。而对于这种属性,通常采用自底向上的方法进行注释。
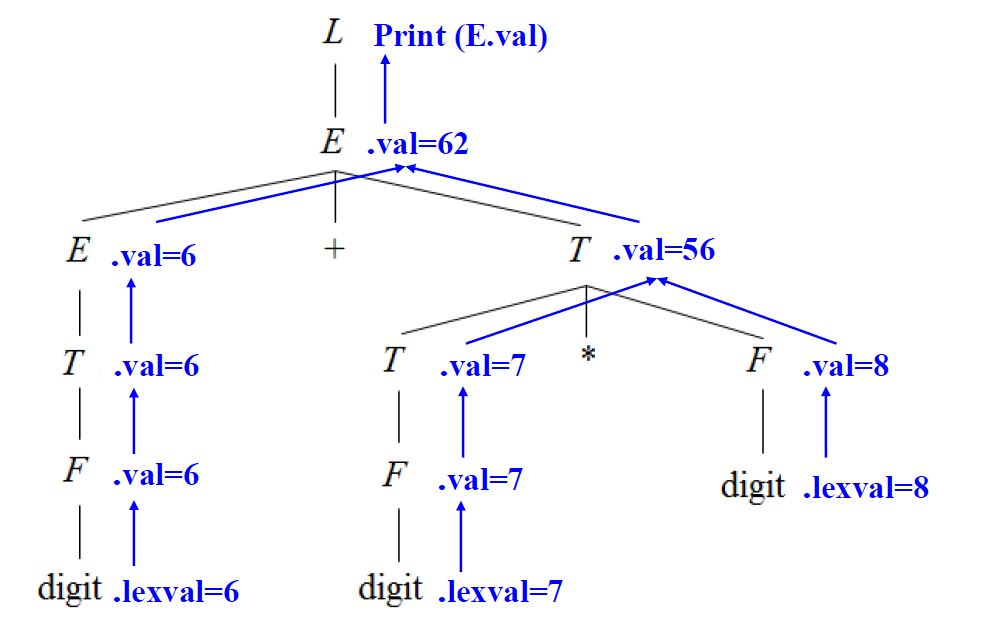
继承属性 出现在产生式右部的某文法符号的继承属性是从其所在产生式的左部非终结符号和/或右部文法符号的属性值计算出来的;在分析树中,一个结点的继承属性是从其兄弟结点和/或父结点的属性值计算出来的。 在分析树中,一个结点的继承属性由其父节点属性或它的兄弟节点属性值决定。 可以用继承属性表示程序设计语言中的上下文之间的依赖关系。
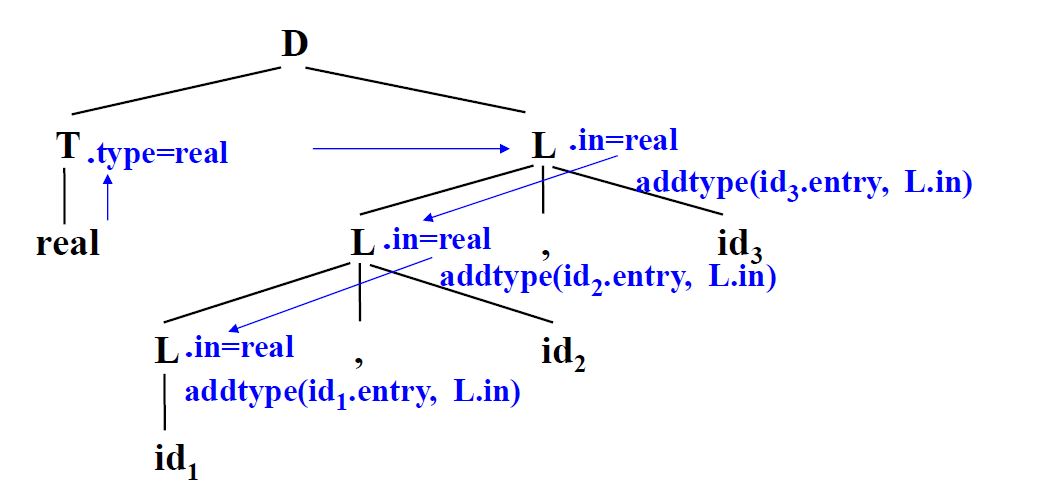
当一个语义规则的唯一目的是产生某个副作用,则通常写成过程调用或程序段,看成是产生式左部非终结符的虚拟综合属性
5.1.2 依赖图
在依赖图中:
- 为每个属性设置一个结点
- 如果属性b依赖于c,那么从属性c的结点有一条有向边连
到属性b的结点。
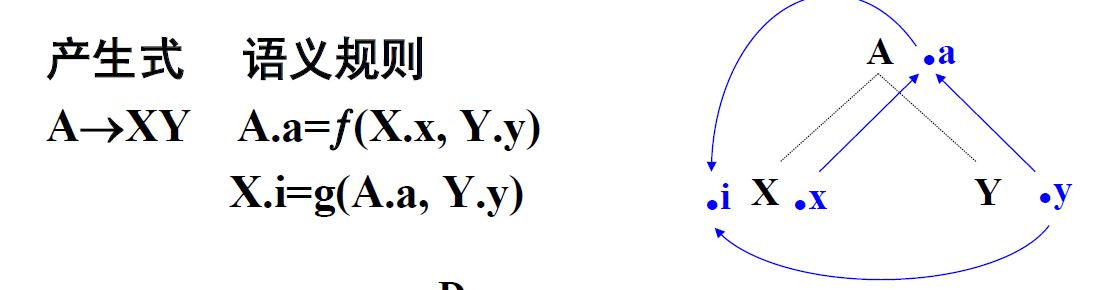
5.1.3 拓扑排序
首先找到入度为0的节点,删除该点及其边,重复该过程至所有点均被删除。
5.1.4 计算顺序
根据拓扑排序的顺序进行求值得到翻译。
总结:最基本的文法用于建立输入符号串的分析树;
- 为分析树构造依赖图;
- 对依赖图进行拓扑排序;
- 从这个序列得到语义规则的计算顺序;
- 照此计算顺序进行求值,得到对输入符号串的翻译。
5.1.5 S-属性与L-属性
- S属性定义:仅仅涉及综合属性,是L属性的子集
- L属性定义:要么是综合属性,要么是由父节点和左兄弟节点决定的继承属性。(右边的不行)
- 对于L属性计算顺序:深度优先遍历分析树
- 进入节点前,计算它的继承属性
- 从节点返回时,计算它的综合属性
5.1.6 翻译方案
S属性翻译方案设计

L属性翻译方案设计
- 计算该继承属性的动作必须出现在相应文法符号之前。
- 一个语义动作不能引用这个动作右边的文法符号的综合属性
- 综合属性的计算动作放在产生式的右端末尾
5.2 S-属性定义的自底向上翻译
5.2.1 S-属性定义的自底向上实现
- 修改分析栈
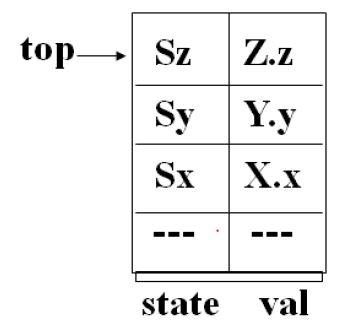
实际上文法符号不需要存入栈中,只是看栈的状态即可。
- 修改分析程序
- 属性随状态一起入栈
- 每个语义规则编写一条代码
- 归约前执行产生式相关的代码
- 当pop和push值相同时,无需代码
- 当进行归约时,ntop=top-|b|+1
- 每一段代码被执行后,top=ntop
注意:一种方式是在分析栈中写出state和val,还有一种更接近人的思维模式,是用文法符号代替状态。(你要是想,可以三个一起写在栈里)
5.2.2 为表达式构造语法树的语法制导定义
语法树:分析树的抽象(压缩)定义
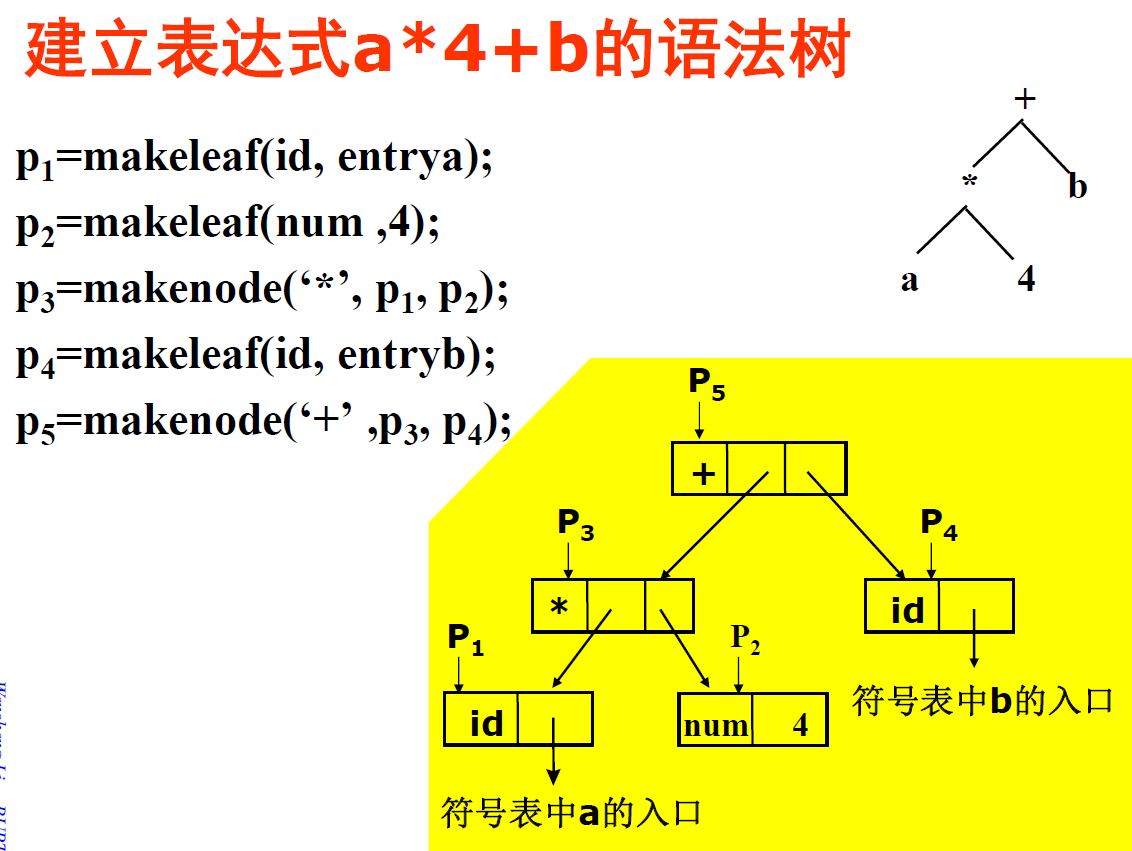
翻译目标:为表达式创造语法树 文法符号的属性:记录所建结点指向相应子树根结点的指针
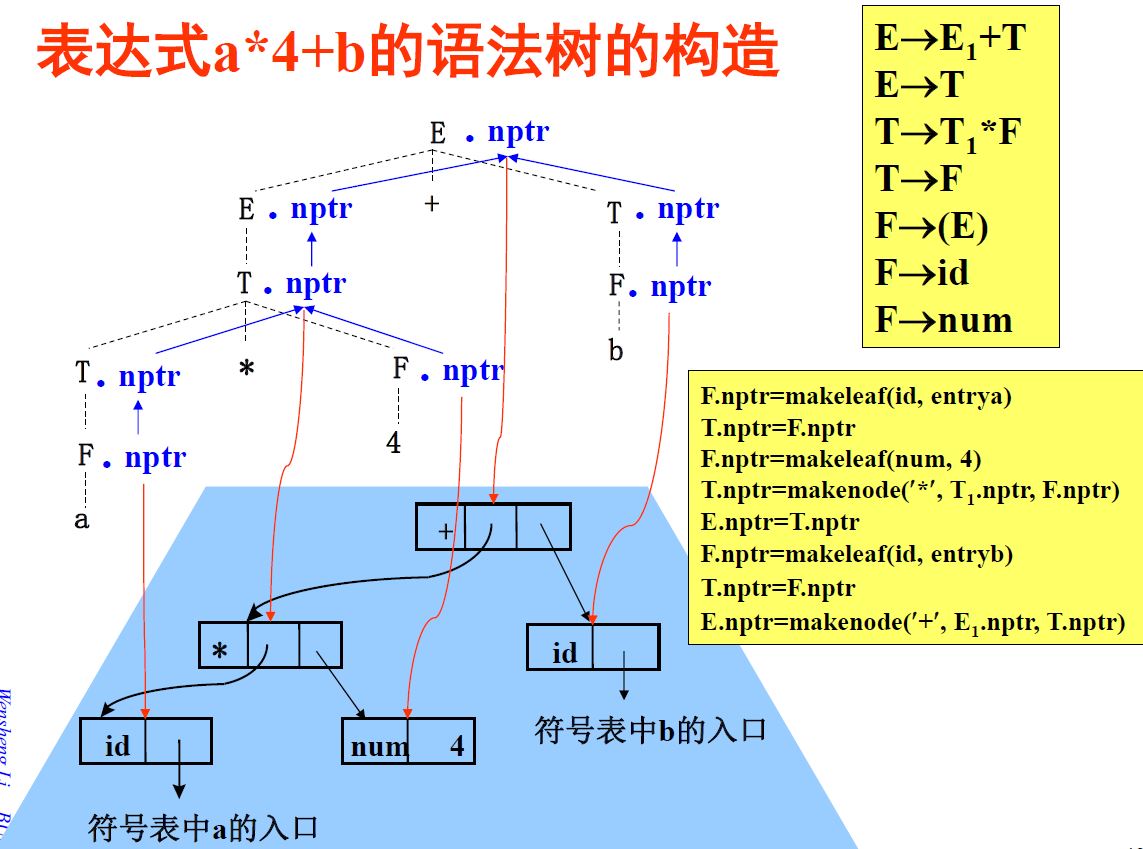 大致过程如下:
根据每次栈中的运算规则,自底向上进行归约和属性运算。方向如同蓝色箭头所指,这里主要涉及的加法和乘法运算是建立内部结点并将结点中的左右指针指向叶子节点或内部节点。
(如果无法理解,打开PPT看看动画过程!相信你会想起来的!)
注意:这是一种后序的深度优先搜索!
大致过程如下:
根据每次栈中的运算规则,自底向上进行归约和属性运算。方向如同蓝色箭头所指,这里主要涉及的加法和乘法运算是建立内部结点并将结点中的左右指针指向叶子节点或内部节点。
(如果无法理解,打开PPT看看动画过程!相信你会想起来的!)
注意:这是一种后序的深度优先搜索!
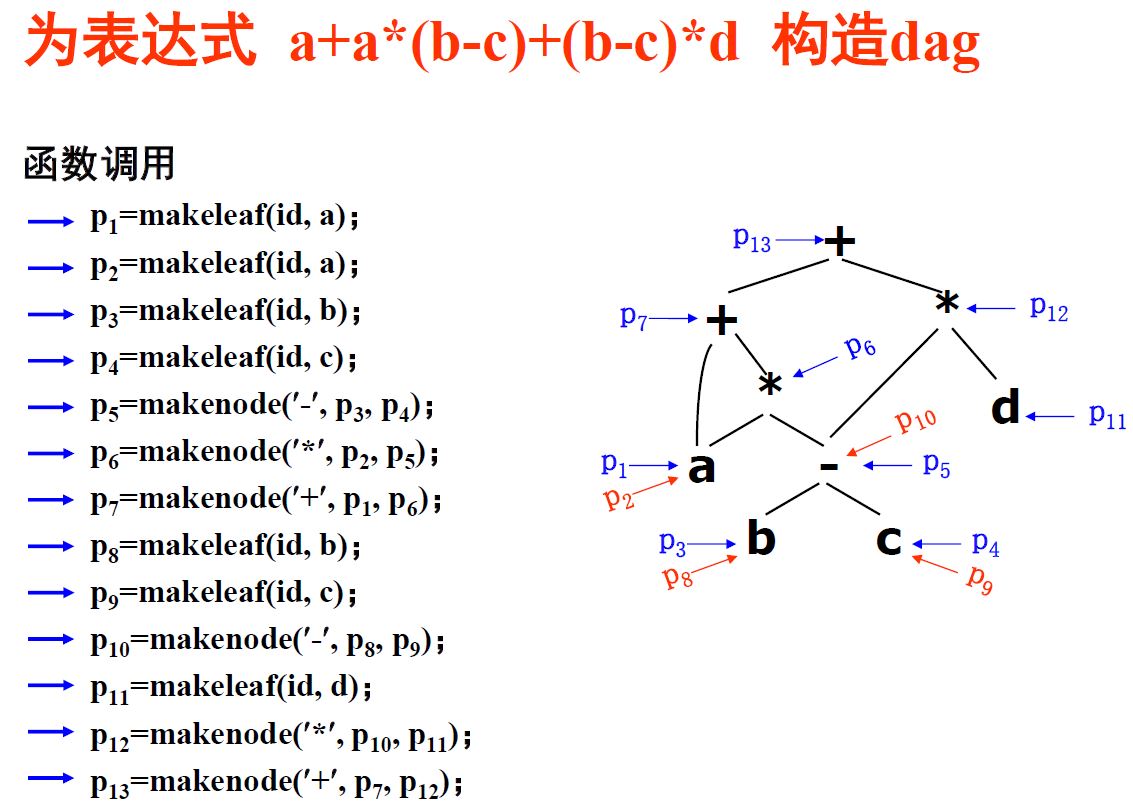
表达式的有向非循环图(dag)
dag与语法树不同之处在于对应一个公共子表达式的结点具有多个父节点(这个性质决定了dag不是树)。换言之,若先前建立过结点,则不会再新建结点,而是直接将指针指向已有结点。
Example:
5.3 L-属性定义的自顶向下翻译
5.3.1 消除翻译方案中的左递归(难点)
对于消除左递归之后新生成的状态R,有以下两种属性:
- 继承属性R.i:表示在R之前已经推导出的子表达式的值
- 综合属性R.s:表示在R完全展开之后得到的表达式的值
消除翻译方案中左递归的一般方法
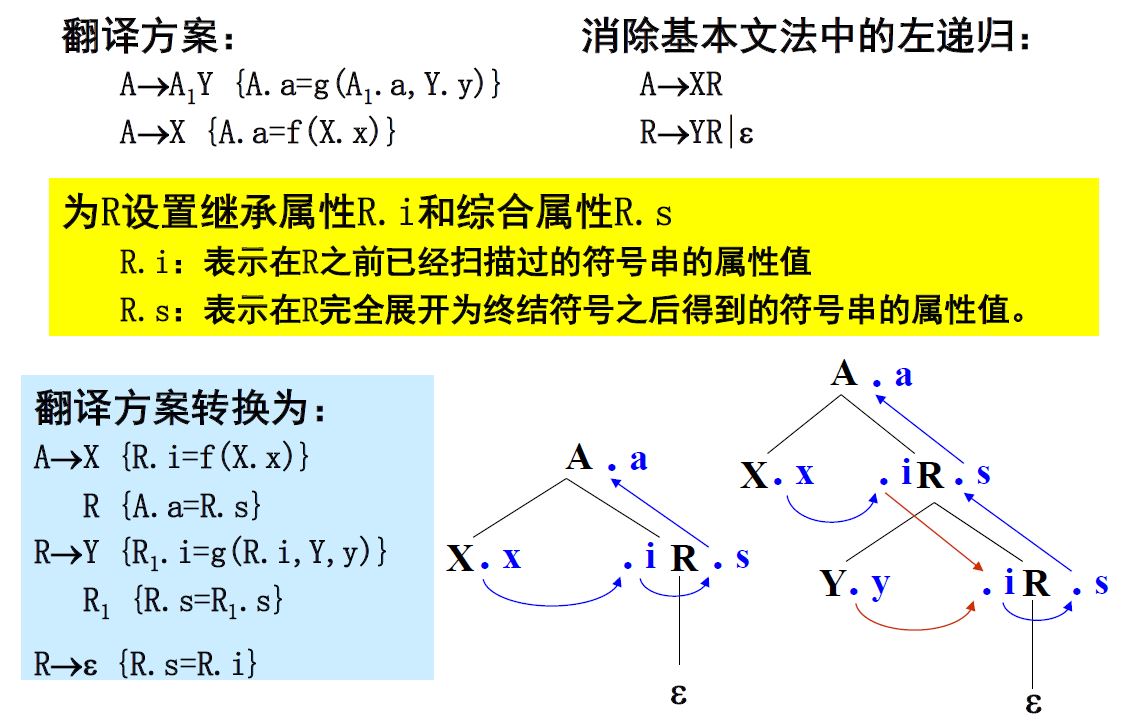 记住右图中计算属性的顺序,红色的为归约时计算继承属性的线路。
记住右图中计算属性的顺序,红色的为归约时计算继承属性的线路。翻译方案: 动作执行时机:在文法符号充分展开之后,在执行产生式后面的部分。
此处看看PPT中例子的动画展示,充分理解在进行归约时如何计算属性
5.3.2 预测翻译程序的设计
为每个非终结符号A建立一个函数(可以是递归函数)
- A的每一个继承属性对应函数的一个形参
- A的综合属性作为函数的返回值
- A中的每一个属性都记作局部变量(这里注意继承属性可是要成为形参的!)
A的函数代码由多个分支组成,对应多个产生式

5.4 L属性定义的自底向上翻译
5.4.1 移走翻译方案中嵌入的语义规则
思想: 等价变换:将所有嵌入的动作都出现在产生式的右端末尾
变换前后的翻译方案是等价的
方法:
- 在基础文法中引入新的产生式,形如:$M \rightarrow \epsilon$
- M:标记非终结符号,用来代替嵌入在产生式中的动作
- 把被M替代的动作放在产生式$M \rightarrow \epsilon$的末尾
5.4.2 直接使用分析栈中的继承属性
复制规则的重要作用:
- 利用栈中的T.type来赋值给未知的L.in。
5.4.3 变换继承属性的计算规则
要想从栈中取得继承属性,当且仅当文法允许属性值在栈中存放的位置可以预测。 但往往继承属性在栈中的位置不可预测! 所以,用标记非终结符号模拟非复制规则的语义规则 为了在分析的同时进行翻译,每个文法符号的属性都要入栈,综合属性可以放在与文法符号对应的栈中Val数组中,继承属性则放在标记非终结符对应的Val数组中,由于是L-属性定义,在标记非终结符处一定可以计算继承属性
引入标记非终结符对语法分析的影响
- LL(1)文法引入标记非终结符后仍是LL(1)文法,不会产生分析冲突
- LR(1)文法引入标记非终结符后不能保证还是LR(1)文法,可能导致分析冲突