
Brandon Zhang
September 22, 2020
Lexcial Analysis & Parsing
I. 词法分析
词法分析器作用:
- 扫描源程序字符流
- 按照源语言的词法规则识别出各类单词符号
- 产生用于语法分析的记号序列
- 词法检查
- 创建符号表 — 为语法分析使用
- 接口:跳过注释、标注错误信息
一、词法分析程序与语法分析程序的关系
1.1 词法分析程序作为独立的一遍

1.2 词法分析程序作为语法分析程序的子程序
词法分析相当于函数,语法分析每一次需要记号时即调用词法分析函数获得记号。
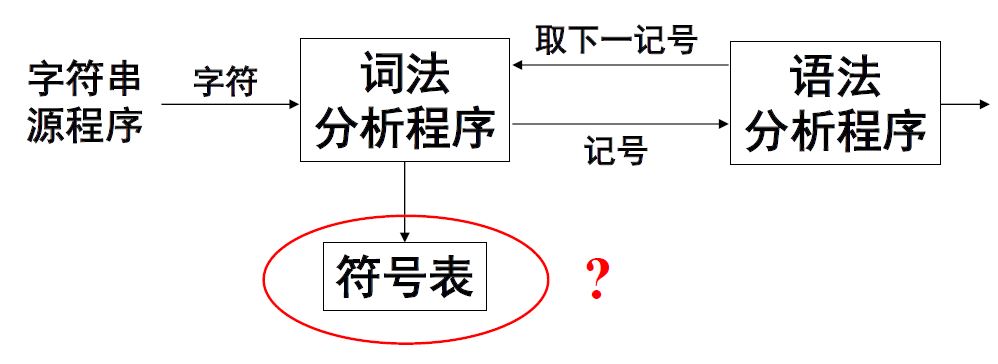
这种操作的好处可以避免中间文件、省去取送记号的工作。
1.3 词法分析程序与语法分析程序作为协同程序
这种方法不常用。
二、词法分析程序的输入与输出
2.1 配对缓冲区
哨兵!!!(EOF)
把一个缓冲器分为大小相同的两半,每半各含N个字符,一般N=1KB或4KB。为了使得判断更为优化,在每个半区后面加上EOF。
 这种做法是为了让缓冲区可以处理超出其范围的字符串。
这种做法是为了让缓冲区可以处理超出其范围的字符串。
2.2 词法分析程序的输出——记号
- 记号:某一类单词符号的类别编码,如id,num
- 模式:某一类单词符号的构成规则,如“有字母开头的字母字符串”
- 单词:某一类单词符号的具体实例,如hello
- 记号的属性
- 作用:记号影响语法分析的决策,属性影响记号的翻译。

- 作用:记号影响语法分析的决策,属性影响记号的翻译。
三、记号的描述和识别
3.1 词法与正规文法
描述语言的标识符、常数、运算符和标点符号等记号的文法
3.2 记号的文法
- 标识符
描述标识符集合的正则表达式:
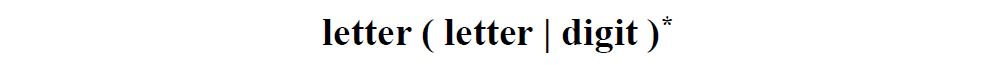 标识符的正规文法(右线性文法)
标识符的正规文法(右线性文法)
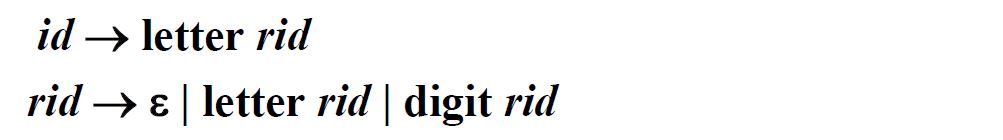
- 常数
整数 描述整数结构的正则表达式:
无符号数
- 运算符
- 分界符
- 关键字
四、词法分析程序的设计与实现
五、软件工具LEX
II. 语法分析
一、简介
- 语法分析程序的任务
- 从源程序记号序列中识别出各类语法成分
- 进行语法检查
- 三种分析器的关系
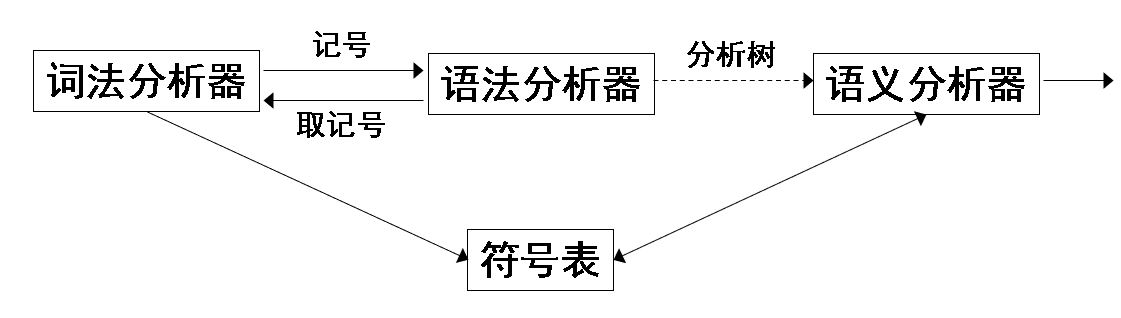
- 语法分析程序的作用
- 输入:记号流/记号序列
- 工作依据:语法规则
- 功能:将记号组合成语法成分、语法检查
- 输出:分析树
- 错误处理
- 常用的分析方法:
- 自顶向下的分析方法
- 自底向上的分析方法
对输入符号串的扫描顺序:==自左向右==
- 错误恢复策略:
- 紧急方式恢复: 抛弃出错的语法结构,方法简单,不会陷入死循环
- 短语级恢复: 局部纠错,防止发生死循环
- 出错产生式: 扩充文法,增加产生错误的产生式
- 全局纠错: 时空代价太大,只有理论上的意义
二、自顶向下分析方法
1. 递归下降分析
为输入符号串建立一个最左推导序列的过程
- 文法的==每一个非终结符号对应一个递归过程==,即可实现这种带回溯的递归下降分析方法。
- 每个过程作为一个布尔过程,一旦发现它的某个产生式与输入串匹配,则用该产生式展开分析树,并返回true,否则分析树不变,返回false。
问题:回溯、穷举
2. 递归调用预测分析
如何克服回溯 让每一个候选式的开始符号各不相同
对文法的要求

- 文法不含左递归
- 非终结符号A的所有候选式的首符集两两互不相交
预测分析程序的构造
- 预测分析程序的转换图
- 转换图的工作过程
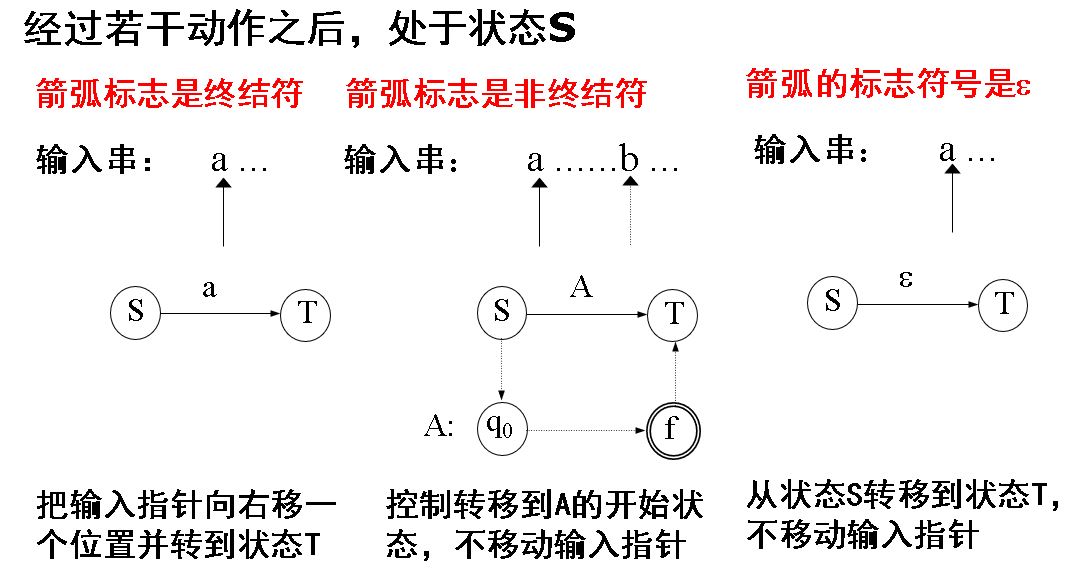
- 转换图的化简
- 预测分析程序的实现
- 如果是终结符,则程序为==匹配该终结符==,输入指针移向下一个记号
- 如果是非终结符,则程序为==调用==该非终结符所对应的子程序,输入指针不移动
- 如果有两个以上的射出边,则使用==分枝语句==在程序中产生相应的分支部分
LL(1)文法 (1) FIRST集合的构造 (2) FOLLOW集合的构造 (3) LL(1)文法的定义

3. 非递归预测分析
使用一张分析表和一个栈联合控制,实现对输入符号串的自顶向下分析。
- 预测分析程序的模型及工作过程
判断LL(1)文法的标准,用第一种方法更为简单
关键:决定哪个产生式运用于非终结符
模型:
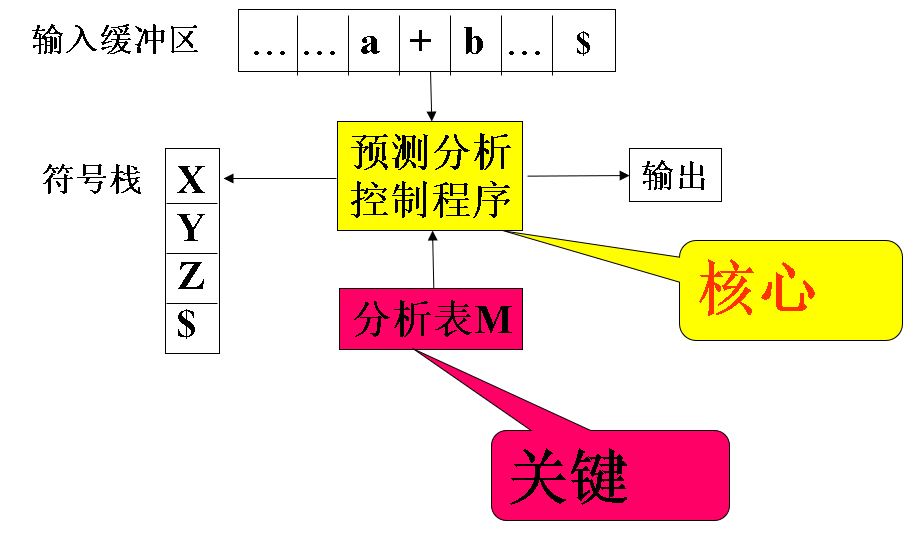
预测分析控制程序 ==这个程序的执行直接看作业例题。==
预测分析表的构造方法

预测分析方法中的错误处理示例
- 栈顶终结符与输入串的首字符不匹配: 解决方法:弹出栈顶的终结符号
- 寻找的分析表表项为空: 解决方法:跳过剩余输入符号串中的若干个符号,直到可以继续进行分析为止(相当于丢掉该非终结符带来的一个树分支)
- 带有同步化信息的分析表
 ==相当于通过FOLLOW集进行判断,若表项没有就加上synch==
==相当于通过FOLLOW集进行判断,若表项没有就加上synch==
三、自底向上分析方法
“可归约串”是句型的“最左素短语”。
- 素短语:句型的一个短语,至少含有一个终结符号,并且除它自身之外不再含有其他更小的素短语。
- 最左素短语:处于句型最左边的那个素短语。
1. “移进-归约”分析方法
- 符号栈:存放文法符号
- 分析过程: (1)把输入符号一个个地移进栈中。 (2)当栈顶的符号串形成某个产生式的一个候选式时,在一定条件下,把该符号串替换(即归约)为该产生式的左部符号。 (3)重复(2),直到栈顶符号串不再是“可归约串”为止。 (4)重复(1)-(3),直到最终归约出文法开始符号S。
2. 规范规约
最右推导的逆过程
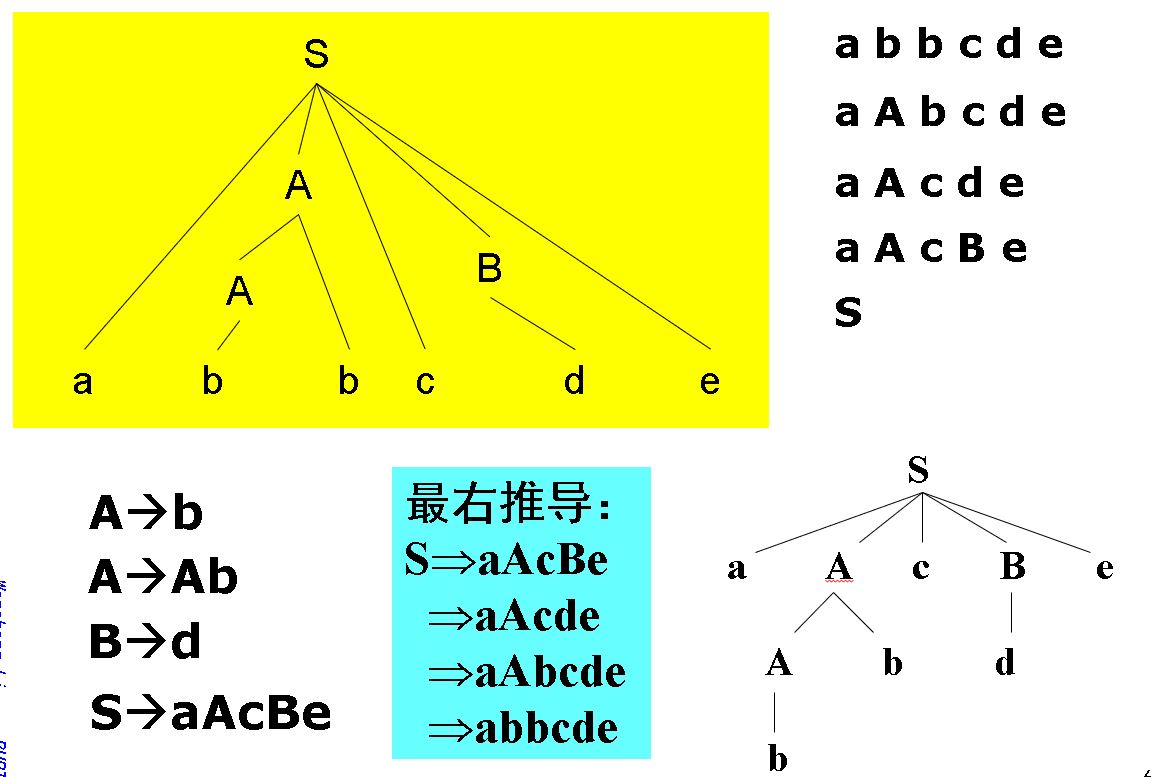
最右推导又称规范推导,由最右推导得到的右句型也称为规范句型,规范推导的逆过程成为规范归约/最左规约。
规范规约的中心问题:如何寻找或确定一个右句型的句柄。
规范句型的特点:句柄之后没有非终结符号
3. “移进-归约”方法实现

- 移进:把下一个输入符号移进到栈顶。
- 归约:用适当的归约符号去替换这个串。
- 接受:宣布分析成功,停止分析。
- 错误处理:调用错误处理程序进行诊断和恢复。
两种冲突:
- “移进-归约”冲突
- “归约-归约”冲突
4. LR分析方法
4.1 LR分析程序
- LR分析程序的模型
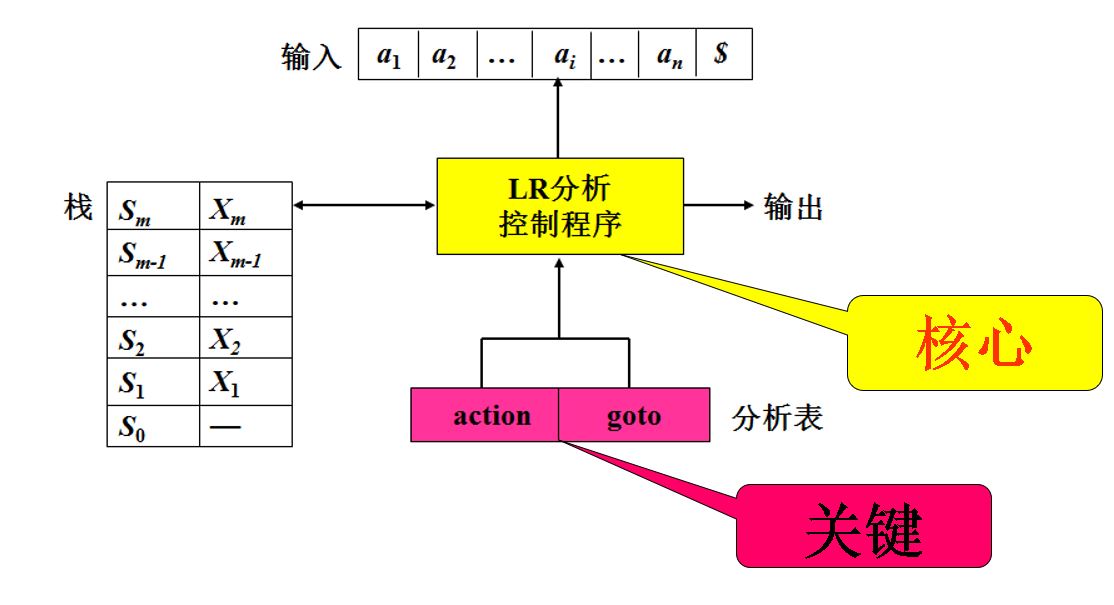
这里需注意栈的存放方式是底$S_0X_1S_1…X_mS_m$顶
- 分析表的结构
- 状态转换表$goto[S_m,X]$
- 动作表$action[S_m,a_i]$
- 构造LR分析表的三种技术
- 简单的LR方法(SLR):易于实现,功能较弱
- 规范的LR方法(LR(1)):功能最强,代价最大
- 向前看的LR方法(LALR):功能和代价介于两者之间,能分析大多数程序设计语言的结构,并且能比较有效地实现
- LR分析控制程序
- 活前缀:一个规范句型的一个前缀,如果不含句柄之后的任何符号,则称它为该句型的一个活前缀。

该程序具体执行结合作业和例子进行复习
4.2 LR分析表构造
- SLR(1)分析表的构造 中心思想:为给定的文法构造一个识别它所有==活前缀==的DFA